En yakın komşu büyük marj - Large margin nearest neighbor
En yakın komşu büyük marj (LMNN)[1] sınıflandırma istatistiksel makine öğrenme algoritma için metrik öğrenme. Öğrenir psödometrik için tasarlandı k-en yakın komşu sınıflandırma. Algoritma dayanmaktadır yarı belirsiz programlama alt sınıfı dışbükey optimizasyon.
Amacı denetimli öğrenme (daha spesifik olarak sınıflandırma), veri örneklerini önceden tanımlanmış sınıflara ayırabilen bir karar kuralını öğrenmektir. k-en yakın komşu kural bir Eğitim etiketli örneklerin veri kümesi (yani sınıflar bilinmektedir). Yeni bir veri örneğini en yakın (etiketli) eğitim örneklerinin çoğunluk oyundan elde edilen sınıfla sınıflandırır. Yakınlık önceden tanımlanmış bir metrik. Büyük marjlı en yakın komşular, k-en yakın komşu kuralının sınıflandırma doğruluğunu iyileştirmek için bu küresel (sözde) ölçüyü denetimli bir şekilde öğrenen bir algoritmadır.
Kurmak
LMNN'nin arkasındaki ana sezgi, eğitim setindeki tüm veri örneklerinin aynı sınıf etiketini paylaşan en az k örnekle çevrildiği bir psödometrik öğrenmektir. Bu başarılırsa, dışarıda bırakma hatası (özel bir durum çapraz doğrulama ) küçültülür. Eğitim verilerinin bir veri kümesinden oluşmasına izin verin , olası sınıf kategorileri kümesinin .


Algoritma türüne ait bir psödometrik öğrenir
- .

İçin iyi tanımlanmak üzere matris olması gerekir pozitif yarı kesin. Öklid metriği özel bir durumdur. kimlik matrisidir. Bu genelleme genellikle (yanlış bir şekilde[kaynak belirtilmeli ]) olarak anılacaktır Mahalanobis metriği.


Şekil 1, metriğin değişkenlikteki etkisini göstermektedir. . İki daire, merkeze eşit uzaklıkta olan noktalar kümesini gösterir . Öklid durumunda bu küme bir çember iken, değiştirilmiş (Mahalanobis) ölçüsü altında bir elipsoid.

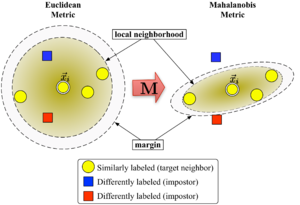
Algoritma, iki tür özel veri noktası arasında ayrım yapar: komşuları hedeflemek ve sahtekarlar.
Komşuları hedefleyin
Hedef komşular öğrenmeden önce seçilir. Her örnek tam olarak var içindeki farklı hedef komşular hepsi aynı sınıf etiketini paylaşıyor . Hedef komşular, olmalı en yakın komşular öğrenilen metriğin altında. Bir veri noktası için hedef komşu kümesini gösterelim gibi .




Sahtekarlar
Bir veri noktasının sahtekarı başka bir veri noktası farklı bir sınıf etiketi ile (ör. ) en yakın komşularından biri olan . Öğrenme sırasında algoritma, eğitim setindeki tüm veri örnekleri için sahtekarların sayısını en aza indirmeye çalışır.


Algoritma
Büyük marj en yakın komşular matrisi optimize eder yardımıyla yarı belirsiz programlama. Amaç iki yönlüdür: Her veri noktası için , komşuları hedeflemek olmalı kapat ve sahtekarlar olmalı uzak. Şekil 1, böyle bir optimizasyonun açıklayıcı bir örnek üzerindeki etkisini göstermektedir. Öğrenilen metrik, giriş vektörüne neden olur aynı sınıftaki eğitim örnekleriyle çevrelenecek. Bir test noktası olsaydı, doğru şekilde şu şekilde sınıflandırılırdı: en yakın komşu kuralı.

İlk optimizasyon hedefine, örnekler ve hedef komşuları arasındaki ortalama mesafeyi en aza indirerek ulaşılır.
- .

İkinci hedef, sahtekarlara mesafelerin cezalandırılmasıyla elde edilir hedef komşulardan bir birimden daha uzakta olan (ve bu nedenle onları yerel mahallenin dışına itmek ). Sonuçta minimize edilecek değer şu şekilde ifade edilebilir:

![{ displaystyle sum _ {i, j in N_ {i}, l, y_ {l} neq y_ {i}} [d ({ vec {x}} _ {i}, { vec {x }} _ {j}) + 1-d ({ vec {x}} _ {i}, { vec {x}} _ {l})] _ {+}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/610f792bc1112ce305344bf3096730af8c5a066a)
Birlikte menteşe kaybı işlevi Bu, sahtekâr yakınlığının marjın dışında kaldığında cezalandırılmamasını sağlar. Tam olarak bir birimin marjı, matrisin ölçeğini düzeltir . Herhangi bir alternatif seçim yeniden ölçeklendirmeye neden olur faktörü ile .
![{ textstyle [ cdot] _ {+} = max ( cdot, 0)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/18812591e56f8034ee8c8497c0f85caaf16818fc)



Son optimizasyon problemi şu hale gelir:





Hiperparametre bazı pozitif sabittir (tipik olarak çapraz doğrulama yoluyla belirlenir). İşte değişkenler (iki tür kısıtlama ile birlikte) maliyet fonksiyonundaki terimi değiştirir. Benzer bir rol oynuyorlar gevşek değişkenler sahtekarlık kısıtlamalarının ihlallerinin kapsamını absorbe etmek. Son kısıtlama şunu sağlar: pozitif yarı kesindir. Optimizasyon problemi, yarı belirsiz programlama (SDP). SDP'ler yüksek hesaplama karmaşıklığından muzdarip olmasına rağmen, bu belirli SDP örneği, sorunun altında yatan geometrik özellikler nedeniyle çok verimli bir şekilde çözülebilir. Özellikle, çoğu sahtekarlık kısıtlaması doğal olarak karşılanır ve çalışma zamanı sırasında zorlanmaları gerekmez (yani değişkenler kümesi) seyrek). Özellikle çok uygun bir çözücü tekniği, çalışma seti Aktif olarak uygulanan küçük bir kısıtlama kümesini tutan ve kalan (muhtemelen karşılanan) kısıtlamaları yalnızca ara sıra doğruluğu sağlamak için izleyen yöntem.


Uzantılar ve verimli çözücüler
LMNN, 2008 belgesinde birden çok yerel ölçüme genişletildi.[2] Bu uzantı, sınıflandırma hatasını önemli ölçüde iyileştirir, ancak daha pahalı bir optimizasyon problemi içerir. Journal of Machine Learning Research'deki 2009 yayınlarında,[3] Weinberger ve Saul, yarı kesin program için etkili bir çözücü türetmiştir. İçin bir metrik öğrenebilir MNIST el yazısı rakamlı veri seti milyarlarca ikili kısıtlamayı içeren birkaç saat içinde. Bir açık kaynak Matlab uygulama ücretsiz olarak mevcuttur yazarlar web sayfası.
Kumal vd.[4] algoritmayı yerel değişmezlikleri çok değişkenli hale getirmek için genişletti polinom dönüşümleri ve iyileştirilmiş düzenlilik.
Ayrıca bakınız
Referanslar
- ^ Weinberger, K. Q .; Blitzer J. C .; Saul L. K. (2006). "Büyük Marjlı En Yakın Komşu Sınıflandırması için Uzaktan Metrik Öğrenme". Sinirsel Bilgi İşleme Sistemlerindeki Gelişmeler. 18: 1473–1480.
- ^ Weinberger, K. Q .; Saul L. K. (2008). "Uzaktan ölçüm için hızlı çözücüler ve verimli uygulamalar" (PDF). Uluslararası Makine Öğrenimi Konferansı Bildirileri: 1160–1167. Arşivlenen orijinal (PDF) 2011-07-24 tarihinde. Alındı 2010-07-14.
- ^ Weinberger, K. Q .; Saul L. K. (2009). "Büyük Marj Sınıflandırması için Uzaktan Metrik Öğrenme" (PDF). Makine Öğrenimi Araştırmaları Dergisi. 10: 207–244.
- ^ Kumar, M.P .; Torr P.H.S .; Zisserman A. (2007). "En yakın komşu sınıflandırıcıya değişmeyen büyük bir marj". IEEE 11. Uluslararası Bilgisayar Görme Konferansı (ICCV), 2007: 1–8. doi:10.1109 / ICCV.2007.4409041. ISBN 978-1-4244-1630-1.