Kod sayfası - Code page
İçinde bilgi işlem, bir kod sayfası bir karakter kodlaması ve bu nedenle, bir dizi yazdırılabilir özel bir ilişki karakterler ve kontrol karakterleri benzersiz sayılarla. Tipik olarak her sayı, tek bir bayttaki ikili değeri temsil eder. (Bazı bağlamlarda bu terimler daha kesin olarak kullanılır; bkz. Karakter kodlaması § Karakter setleri, karakter haritaları ve kod sayfaları.)
"Kod sayfası" terimi IBM 's EBCDIC tabanlı ana bilgisayar sistemleri,[1] fakat Microsoft, SAP,[2] ve Oracle Corporation[3] bu terimi kullanan birkaç satıcıdan biridir. Satıcıların çoğu, kendi karakter kümelerini bir adla tanımlar. Çok sayıda karakter kümesinin olduğu durumda (IBM'de olduğu gibi), karakter kümelerini bir sayı aracılığıyla tanımlamak, onları ayırt etmenin uygun bir yoludur. Başlangıçta, belirtilen kod sayfası numaraları sayfa sayılar IBM standart karakter seti kılavuzunda,[4][5][6] uzun süredir devam etmeyen bir durum. Bir kod sayfası sistemi kullanan satıcılar, başka bir adla daha iyi bilinse bile, kendi kod sayfası numaralarını bir karakter kodlamasına tahsis eder; Örneğin, UTF-8 IBM'de 1208, Microsoft'ta 65001 ve SAP'de 4110 sayfa numaraları atanmıştır.
Hewlett Packard benzer bir kavramı kullanır HP-UX işletim sistemi ve Yazıcı Komut Dili[7] Yazıcılar için (PCL) protokolü (HP yazıcılar için veya değil). Ancak terminoloji farklıdır: Başkalarının karakter seti, HP bir simge setive IBM veya Microsoft'un kod sayfası, HP bir simge seti kodu. HP bir dizi simge seti geliştirdi,[8][9] her biri, hem kendi karakter kümelerini hem de diğer satıcıların karakter kümelerini kodlamak için ilişkili bir simge kümesi koduna sahiptir.
Çok sayıda karakter seti, birçok satıcının Unicode.
Kod sayfası numaralandırma sistemi
IBM, bir bilgisayar sisteminin veya bilgisayar sistemleri koleksiyonunun karşılaşabileceği her karakter kodlamasına küçük, ancak küresel olarak benzersiz 16 bitlik bir sayıyı sistematik olarak atama kavramını tanıttı. Numaralandırma şemasının IBM kökeni, en küçük (ilk) numaraların IBM'in EBCDIC kodlamasının varyasyonlarına atanması ve biraz daha büyük sayıların IBM'in varyasyonlarına atıfta bulunması gerçeğinde yansıtılmaktadır. genişletilmiş ASCII PC donanımında kullanıldığı şekliyle kodlama.
Serbest bırakılmasıyla PC DOS sürüm 3.3 (ve neredeyse aynı MS-DOS 3.3) IBM, kod sayfası numaralandırma sistemini normal PC kullanıcılarına tanıttı, çünkü kod sayfası numaraları (ve "kod sayfası" ifadesi), işletim sisteminin tüm bölümleri tarafından kullanılan karakter kodlamasının bir sistematik yol.[10]
IBM ve Microsoft 1990'larda işbirliği yapmayı bıraktıktan sonra, iki şirket, atanmış kod sayfası numaralarını birbirinden bağımsız olarak sürdürdü ve bu da bazı çakışan atamalara neden oldu. En az bir üçüncü taraf satıcı (Oracle ) ayrıca kendi farklı sayısal atamalar listesine sahiptir.[3] IBM'in mevcut atamaları, bunların CCSID havuz, Microsoft'un atamaları ise MSDN.[11] Ek olarak, adların ve yaklaşık IANA'nın (İnternette Atanan Numaralar Kurumu ) herhangi bir Windows makinesinde yüklü kod sayfalarının kısaltmaları, o makinedeki Kayıt Defterinde bulunabilir (bu bilgi, aşağıdaki gibi Microsoft programları tarafından kullanılır. Internet Explorer ).
En iyi bilinen kod sayfaları, CJK diller ve Vietnam, tüm kod noktalarını sekiz bite sığdırın ve her kod noktasını tek bir karaktere eşlemekten başka bir şey içermez; dahası, karakterleri birleştirme, karmaşık komut dosyaları, vb. gibi teknikler dahil değildir.
Standart metin modu (VGA uyumlu ) PC grafik donanımı, 8 bitlik bir kod sayfası kullanılarak oluşturulmuştur, ancak bir miktar renk derinliğinden ödün vererek aynı anda ikisini kullanmak mümkündür ve kolay geçiş için ekran adaptöründe sekize kadar saklanabilir.[12] Bu tür donanıma yüklenebilecek çeşitli üçüncü taraf kod sayfası yazı tipleri vardı. Bununla birlikte, işletim sistemi satıcılarının bir grafik modunda çalışan ve bu donanım sınırlamasını tamamen atlayan kendi karakter kodlama ve işleme sistemlerini sağlaması artık olağan bir durumdur. Bununla birlikte, e-posta ve web sayfaları gibi çeşitli protokollerde kullanım için IETF ve IANA tarafından belirtilenler gibi dize tanımlayıcılara etkili bir alternatif olarak, bir kod sayfası numarasıyla karakter kodlamalarına atıfta bulunma sistemi uygulanabilir olmaya devam etmektedir.
ASCII ile İlişki
Şu anda kullanımda olan kod sayfalarının çoğu, ASCII 128 kontrol kodunu ve yazdırılabilir karakteri temsil eden 7 bitlik bir kod. Uzak geçmişte, ASCII kodunun 8 bit uygulamaları, üst biti sıfıra ayarladı veya bir eşlik biti ağ veri iletimlerinde. Üst bit, karakter verilerini temsil etmek için kullanılabilir hale getirildiğinde, toplam 256 karakter ve kontrol kodu temsil edilebilir. Çoğu satıcı (IBM dahil), bu genişletilmiş aralığı, yalnızca metin çıktı aygıtlarında ilkel grafiklerin taklit edilmesine izin veren çeşitli diller ve grafik öğeleri tarafından kullanılan karakterleri kodlamak için kullandı. IBM'in EBCDIC kodlamalarının varyantları için her zaman yaptığı gibi, bu "genişletilmiş ASCII karakter kümeleri" için resmi bir standart yoktu ve satıcılar varyantları kod sayfaları olarak adlandırdılar.
Unicode ile İlişki
Unicode, dijital olarak depolanan metinleri işlerken farklı kod sayfaları arasında ayrım yapma ihtiyacını ortadan kaldırarak, şu anda ve geçmişte kullanılan tüm insan dillerinden tüm karakterleri tek karakter numaralandırmaya (etkin bir şekilde tek bir büyük tek kod sayfası) dahil etme çabasıdır. Unicode, birçok eski kod sayfasıyla geriye dönük uyumluluğu korumaya çalışır ve tasarım sürecinde bazı kod sayfalarını 1: 1 kopyalar. Unicode'un açık bir tasarım hedefi, bu hedefe her zaman ulaşılamamasına rağmen, tüm yaygın eski kod sayfaları arasında gidiş dönüş dönüşüme izin vermekti. IBM ve Microsoft gibi bazı satıcılar, Unicode kodlamalarına anakronik olarak atanmış kod sayfası numaralarına sahiptir. Bu kural, kod sayfası numaralarının ikili olarak depolanan verilerle karşılaşıldığında doğru kod çözme algoritmasını tanımlamak için meta veriler olarak kullanılmasına izin verir.
IBM kod sayfaları
EBCDIC tabanlı kod sayfaları
Bu kod sayfaları, IBM tarafından EBCDIC karakter kümelerinde şu amaçlarla kullanılmaktadır: ana bilgisayar bilgisayarlar.
- 1 - ABD WP, Orijinal
- 2 - ABD
- 3 - ABD Muhasebesi, Sürüm A
- 4 - ABD
- 5 - ABD
- 6 - Latin Amerika
- 7 - Almanya F.R. / Avusturya
- 8 - Almanya F.R.
- 9 - Fransa, Belçika
- 10 - Kanada (İngilizce)
- 11 - Kanada (Fransızca)
- 12 - İtalya
- 13 - Hollanda
- 14 –
- 15 - İsviçre (Fransızca)
- 16 - İsviçre (Fransızca / Almanca)
- 17 - İsviçre (Almanca)
- 18 - İsveç / Finlandiya
- 19 - İsveç / Finlandiya WP, sürüm 2
- 20 - Danimarka / Norveç
- 21 - Brezilya
- 22 - Portekiz
- 23 - Birleşik Krallık
- 24 - Birleşik Krallık
- 25 - Japonya (Latin)
- 26 - Japonya (Latin)
- 27 - Yunanistan (Latin)
- 28 –
- 29 - İzlanda
- 30 - Türkiye
- 31 - Güney Afrika
- 32 - Çekoslovakya (Çekçe / Slovakça)
- 33 - Çekoslovakya
- 34 - Çekoslovakya
- 35 - Romanya
- 36 - Romanya
- 37 - ABD / Kanada - CECP (euro ile aynı: 1140 | 1140)
- 37-2 - C / 370 tarafından kullanılan gerçek 3279 APL kod sayfası. Bu, düzeltme işareti ve ters çevrilmiş olmayan işaret hariç 1047'ye çok yakındır. SHARE'in varlığına işaret etmesine rağmen, IBM tarafından resmi olarak tanınmamaktadır.[13]
- 38 - ABD ASCII
- 39 - Birleşik Krallık / İsrail
- 40 - Birleşik Krallık
- 251 - Çin
- 252 - Polonya
- 254 - Macaristan
- 256 - Uluslararası # 1 (yerini 500 | 500 almıştır)
- 257 - Uluslararası # 2
- 258 - Uluslararası # 3
- 259 - Semboller, Set 7
- 260 - Kanada Fransızcası - 116
- H.264 - Yazdırma Eğitimi ve Metin işleme genişletildi
- 273 - Almanya F.R./Avusturya - CECP (euro ile aynı: 1141 | 1141)
- 274 - Eski Belçika Kod Sayfası
- 275 - Brezilya - CECP
- 276 - Kanada (Fransızca) - 94
- 277 - Danimarka, Norveç - CECP (euro ile aynı: 1142 | 1142)
- 278 - Finlandiya, İsveç - CECP (euro ile aynı: 1143 | 1143)
- 279 - Fransızca - 94[13]
- 280 - İtalya - CECP (euro ile aynı: 1144 | 1144)
- 281 - Japonya (Latin) - CECP
- 282 - Portekiz - CECP
- 283 - İspanya - 190[13]
- 284 - İspanya / Latin Amerika - CECP (euro ile aynı: 1145 | 1145)
- 285 - Birleşik Krallık - CECP (euro ile aynı: 1146 | 1146)
- 286 - Avusturya / Almanya F.R. Alternatif
- 287 - Danimarka / Norveç Alternatif
- 288 - Finlandiya / İsveç Alternatif
- 289 - İspanya Alternatif
- 290 - Japonca (Katakana) Genişletilmiş
- 293 - APL
- 297 - Fransa (euro ile aynı: 1147)[13]
- 298 - Japonya (Katakana)
- 300 - Japonya (Kanji) DBCS (JIS X 0213 için)
- 310 - Grafik Kaçış APL / TN
- 320 - Macaristan
- 321 - Yugoslavya
- 322 - Türkiye
- 330 - Uluslararası # 4
- 351 - GDDM varsayılanı
- 352 - Baskı ve yayınlama seçeneği
- 353 - BCDIC-A
- 355 - PTTC / BCD standart seçeneği
- 357 - PTTC / BCD H seçeneği
- 358 - PTTC / BCD Yazışma seçeneği
- 359 - PTTC / BCD Monocase seçeneği
- 360 - PTTC / BCD Duocase seçeneği
- 361 - EBCDIC Publishing International
- 363 - Semboller, set 8
- 382 - EBCDIC Publishing Austria, Almanya F.R. Alternatif
- 383 - EBCDIC Publishing Belgium
- 384 - EBCDIC Publishing Brazil
- 385 - EBCDIC Publishing Canada (Fransızca)
- 386 - EBCDIC Publishing Danimarka, Norveç
- 387 - EBCDIC Publishing Finlandiya, İsveç
- 388 - EBCDIC Publishing France
- 389 - EBCDIC Yayınları İtalya
- 390 - EBCDIC Yayıncılık Japonya (Latin)
- 391 - EBCDIC Yayınları Portekiz
- 392 - EBCDIC Publishing İspanya, Filipinler
- 393 - EBCDIC Publishing Latin America (İspanyolca Konuşan)
- 394 - EBCDIC Publishing China (Hong Kong), İngiltere, İrlanda
- 395 - EBCDIC Publishing Australia, Yeni Zelanda, ABD, Kanada (İngilizce)
- 410 - Kiril (düzeltmeler: 880, 1025, 1154)
- 420 - Arapça
- 421 - Mağrip / Fransızca
- 423 - Yunanca (875 ile değiştirildi)
- 424 - İbranice (Bülten Kodu)
- 425 - OS / 390 Open Edition için Arapça / Latince
- 435 - Teletekst İzomorfik
- 500 - Uluslararası # 5 (ECECP; 256'nın yerini alır) (euro ile aynı: 1148)
- 803 - İbranice Karakter Seti A (Eski Kod)
- 829 - Ana Matematik Sembolleri - Yayınlama
- 833 - Korece Genişletilmiş (SBCS)
- 834 - Kore Hangul (KSC5601; UDC'li DBCS)
- 835 - Geleneksel Çince DBCS
- 836 - Basitleştirilmiş Çince Genişletilmiş
- 837 - Basitleştirilmiş Çince DBCS
- 838 - Düşük İşaretli ve Aksanlı Karakterli Tay Dili (euro ile aynı: 1160)
- 839 - Tayland DBCS
- 870 - Latin 2 (euro ile aynı: 1153) (revizyon: 1110)
- 871 - İzlanda (euro ile aynı: 1149)[13]
- 875 - Yunanca (423'ün yerine geçer)
- 880 - Kiril (410 revizyonu) (revizyonlar: 1025, 1154)
- 881 - Amerika Birleşik Devletleri - 5080 Grafik Sistemi
- 882 - Birleşik Krallık - 5080 Grafik Sistemi
- 883 - İsveç - 5080 Grafik Sistemi
- 884 - Almanya - 5080 Grafik Sistemi
- 885 - Fransa - 5080 Grafik Sistemi
- 886 - İtalya - 5080 Grafik Sistemi
- 887 - Japonya - 5080 Grafik Sistemi
- 888 - Fransa AZERTY - 5080 Grafik Sistemi
- 889 - Tayland
- 890 - Yugoslavya
- 892 - EBCDIC, OCR A
- 893 - EBCDIC, OCR B
- 905 - Latince 3
- 918 - Urduca İki Dilli
- 924 - Latince 9
- 930 - Japonya MIX (290 + 300) (euro ile aynı: 1390)
- 931 - Japonya MIX (37 + 300)
- 933 - Kore MIX (833 + 834) (euro ile aynı: 1364)
- 935 - Basitleştirilmiş Çince MIX (836 + 837) (euro ile aynı: 1388)
- 937 - Geleneksel Çince MIX (37 + 835) (euro ile aynı: 1371)
- 939 - Japonya MIX (1027 + 300) (euro ile aynı: 1399)
- 1001 - MICR
- 1002 - EBCDIC DCF Sürüm 2 Uyumluluğu
- 1003 - EBCDIC DCF, ABD Metin alt kümesi
- 1005 - EBCDIC İzomorfik Metin İletişimi
- 1007 - EBCDIC Arapça (XCOM2)
- 1024 - EBCDIC T.61
- 1025 - Kiril, Çok Dilli (euro ile aynı: 1154) (880 revizyonu)
- 1026 - EBCDIC Türkiye (Latin 5) (euro ile aynı: 1155) (o ülkede 905'in yerini alıyor)
- 1027 - Japonca (Latin) Genişletilmiş (JIS X 0201 Genişletilmiş)
- 1028 - EBCDIC Yayınları İbranice
- 1030 - Japonca (Katakana) Genişletilmiş
- 1031 - Japonca (Latin) Genişletilmiş
- 1032 - MICR, E13-B Birleşik
- 1033 - MICR, CMC-7 Kombine
- 1037 - Kore - 5080/6090 Grafik Sistemi
- 1039 - GML Uyumluluğu
- 1047 - Latin 1 / Açık Sistemler[13]
- 1068 - DCF Uyumluluğu
- 1069 - Latince 4
- 1070 - ABD / Kanada Sürüm 0 ([[Kod sayfası 37 Sürüm 0)
- 1071 - Almanya F.R. / Avusturya
- 1073 - Brezilya
- 1074 - Danimarka, Norveç
- 1075 - Finlandiya, İsveç
- 1076 - İtalya
- 1077 - Japonya (Latin)
- 1078 - Portekiz
- 1079 - İspanya / Latin Amerika Sürüm 0 ([[Kod sayfası 284 Sürüm 0)
- 1080 - Birleşik Krallık
- 1081 - Fransa Sürüm 0 ([[Kod sayfası 297 Sürüm 0)
- 1082 - İsrail (İbranice)
- 1083 - İsrail (İbranice)
- 1084 - Uluslararası # 5 Sürüm 0 ([[Kod sayfası 500 Sürüm 0)
- 1085 - İzlanda
- 1087 - Sembol Seti
- 1091 - Değiştirilmiş Semboller, Set 7
- 1093 - IBM Logosu[14]
- 1097 - Farsça İki Dilli
- 1110 - Latince 2 (870'in Revizyonu)
- 1112 - Baltık Çok Dilli (euro ile aynı: 1156)
- 1113 - Latince 6
- 1122 - Estonya (euro ile aynı: 1157)
- 1123 - Kiril, Ukrayna (euro ile aynı: 1158)
- 1130 - Vietnamca (euro ile aynı: 1164)
- 1132 - Lao EBCDIC
- 1136 - Hitachi Katakana
- 1137 - Devanagari EBCDIC
- 1140 - ABD, Kanada, vb. ECECP (euro olmadan aynı: 37) (Geleneksel Çince versiyonu: 1159)
- 1141 - Avusturya, Almanya ECECP (euro'suz aynı: 273)
- 1142 - Danimarka, Norveç ECECP (euro'suz aynı: 277)
- 1143 - Finlandiya, İsveç ECECP (euro'suz aynı: 278)
- 1144 - İtalya ECECP (euro'suz aynı: 280)
- 1145 - İspanya, Latin Amerika (İspanyolca) ECECP (euro olmadan aynı: 284)
- 1146 - UK ECECP (euro'suz aynı: 285)
- 1147 - Fransa ECECP euro ile (euro olmadan aynı: 297)
- 1148 - Euro ile Uluslararası ECECP (euro olmadan aynı: 500)
- 1149 - İzlanda EÇEB'i euro ile (euro olmadan aynı: 871)
- 1150 - Kutu karakterleriyle Korece Genişletilmiş
- 1151 - Kutu karakterleriyle Genişletilmiş Basitleştirilmiş Çince
- 1152 - Kutu karakterleriyle Genişletilmiş Geleneksel Çince
- 1153 - Euro ile Latin 2 Çok dilli (euro'suz aynı: 870)
- 1154 - Kiril, Çok dilli, euro ile (euro olmadan aynı: 1025; eski sürüm * 1166)
- 1155 - Euro ile Türkiye (euro olmadan aynı: 1026)
- 1156 - Euro ile Baltık Multi (euro olmadan aynı: 1112)
- 1157 - Euro ile Estonya (euro olmadan aynı: 1122)
- 1158 - Kiril, Ukrayna euro ile (euro olmadan aynı: 1123)
- 1159 - T-Çin EBCDIC (* 1140'ın Geleneksel Çince euro güncellemesi)
- 1160 - Düşük İşaretli Tay ve Aksanlı Karakterler euro ile (euro olmadan aynı: 838)
- 1164 - Euro ile Vietnamlı (euro olmadan aynı: 1130)
- 1165 - Latin 2 / Açık Sistemler
- 1166 - Kiril Kazakça
- 1278 - EBCDIC Adobe (PostScript) Standart Kodlama
- 1279 - Hitachi Japon Katakana Sunucusu[6]
- 1303 - EBCDIC Barkod
- 1364 - Kore MIX (833 + 834 + euro) (euro olmadan aynı: 933)
- 1371 - Geleneksel Çince MIX (1159 + 835) (euro olmadan aynı: 937)
- 1376 - HKSCS için Geleneksel Çince DBCS Ana Bilgisayar uzantısı
- 1377 - Karma Konak HKSCS Büyüyor (37 + 1376)
- 1388 - Basitleştirilmiş Çince MIX (euro olmadan aynı: 935) (836 + 837 + euro)
- 1390 - Basitleştirilmiş Çince MIX Japan MIX (euro olmadan aynı: 930) (290 + 300 + euro)
- 1399 - Japonya MIX (1027 + 300 + euro) (euro olmadan aynı: 939)
DOS kod sayfaları
Bu kod sayfaları, IBM tarafından kendi PC DOS işletim sistemi. Bu kod sayfaları başlangıçta doğrudan metin modu ile kullanılan grafik bağdaştırıcılarının donanımı IBM PC ve karakter kümeleri yalnızca fontu içeren bir ROM yongası fiziksel olarak değiştirilerek değiştirilebilen orijinal MDA ve CGA adaptörleri dahil olmak üzere klonları. Bu bağdaştırıcıların arabirimi (VGA gibi sonraki tüm bağdaştırıcılar tarafından taklit edilir) tipik olarak her yazı tipi / kodlamada yalnızca 256 karakter içeren tek baytlık karakter kümeleriyle sınırlıydı (VGA biraz daha büyük karakter kümeleri için kısmi destek eklemesine rağmen).
- 301 - IBM-PC Japan (Kanji) DBCS
- 437 - Orijinal IBM PC donanım kodu sayfası
- 720 - Arapça (Şeffaf ASMO)
- 737 – Yunan
- 775 - Latince-7
- 808 - Euro ile Rusça (euro olmadan aynı: 866 )
- 848 - Ukraynaca euro ile (euro olmadan aynı: 1125 )
- 849 - Belarusça euro ile (euro olmadan aynı: 1131 )
- 850 - Latince-1
- 851 - Yunanca
- 852 - Latince-2
- 853 - Latince-3
- 855 – Kiril (euro ile aynı: 872 )
- 856 – İbranice
- 857 - Latince-5
- 858 - Latin-1 ile euro sembol
- 859 - Latince-9
- 860 – Portekizce
- 861 – İzlandaca
- 862 – İbranice
- 863 – Kanadalı Fransız
- 864 – Arapça
- 865 – Danimarka dili /Norveççe
- 866 - Belarusça, Rusça, Ukraynaca (euro ile aynı: 808 )
- 867 – İbranice + euro (CP862'ye göre) (çakışan kimlik: NEC Çekçe (Kamenický), bu kod sayfasından önce oluşturulmuş olan)
- 868 – Urduca
- 869 – Yunan
- 872 - Euro ile Kiril alfabesi (euro olmadan aynı: 855 )
- 874 - Düşük Tonlu İşaretler ve Antik Karakterlerle Tay Dili (Windows 874 ile çakışan kimlik; euro ile sürüm: 1161 Windows sürümü: IBM 1162 )
- 876 - OCR A
- 877 - OCR B
- 878 – KOI8-R
- 891 - Kore PC SBCS
- 898 - IBM-PC WP Çok Dilli
- 899 - IBM-PC Sembolü
- 903 - Basitleştirilmiş Çince PC SBCS
- 904 - Geleneksel Çince PC SBCS
- 906 - Uluslararası Set # 5 3812/3820
- 907 - ASCII APL (3812)
- 909 - IBM-PC APL2 Genişletilmiş
- 910 - IBM-PC APL2
- 911 - IBM-PC Japonya # 1
- 926 - Korece PC DBCS
- 927 - Geleneksel Çince PC DBCS
- 928 - Basitleştirilmiş Çince PC DBCS
- 929 - Tay PC DBCS
- 932 - IBM-PC Japan MIX (DOS / V) (DBCS) (897 + 301 ) (Windows 932 ile çakışan kimlik; Windows sürümü IBM 943'tür)
- 934 - IBM-PC Kore MIX (DOS / V) (DBCS) (891 + 926 )
- 936 - IBM-PC Basitleştirilmiş Çince MIX (gb2312) (DOS / V) (DBCS) (903 + 928 ) (Windows 936 ile çakışan kimlik; Windows sürümü IBM 1386'dır)
- 938 - IBM-PC Geleneksel Çince MIX (DOS / V, OS / 2) (904 + 927 )
- 942 - IBM-PC Japan MIX (Japon SAA (OS / 2)) (1041 + 301 )
- 943 - IBM-PC Japan AÇIK (897 + 941 ) (Windows CP 932)
- 944 - IBM-PC Korea MIX (Kore SAA (OS / 2)) (1040 + 926 )
- 946 - IBM-PC Basitleştirilmiş Çince (Basitleştirilmiş Çince SAA (OS / 2)) (1042 + 928 )
- 948 - IBM-PC Geleneksel Çince (Geleneksel Çince SAA (OS / 2)) (1043 + 927 )
- 949 - Korece (Extended Wansung (ks_c_5601-1987)) (1088 + 951 ) (Windows 949 ile çakışan kimlik (Birleşik Hangul Kodu); Windows sürümü IBM 1363'tür)
- 951 - Korece DBCS (IBM KS Kodu) (Windows 951 ile çakışan kimlik, dosya adına bağlı olarak HKSCS'de bulunan bazı PUA Unicode karakterleri için Unicode eşlemeleri içeren bir Windows 950 hacklemesi)
- 1034 - Yazıcı Uygulaması - Sevkiyat Etiketi, Set # 2
- 1040 - Korece Genişletilmiş
- 1041 - Japonca Genişletilmiş (JIS X 0201 Genişletilmiş)
- 1042 - Basitleştirilmiş Çince Genişletilmiş
- 1043 - Geleneksel Çince Genişletilmiş
- 1044 - Yazıcı Uygulaması - Gönderi Etiketi, Set # 1
- 1046 - Arapça Genişletilmiş (Euro)
- 1086 - IBM-PC Japonya # 1
- 1088 - Revize Edilmiş Korece (SBCS)
- 1092 - IBM-PC Değiştirilmiş Semboller
- 1098 – Farsça
- 1108 - DITROFF Base Uyumluluğu
- 1109 - DITROFF Özel Uyumluluğu
- 1115 - IBM-PC Çin Halk Cumhuriyeti
- 1116 - Estonca
- 1117 - Letonca
- 1118 - Litvanya (IBM'in Lika's uygulaması kod sayfası 774 )
- 1119 - Litvanca ve Rusça (IBM'in Lika's uygulaması kod sayfası 772 )
- 1125 - Kiril, Ukraynaca (euro ile aynı: 848 ) (IBM değişikliği RUSCII )
- 1127 - IBM-PC Arapça / Fransızca
- 1131 - IBM-PC Verileri, Kiril, Beyaz Rusça (euro ile aynı: 849 )
- 1139 - Japonya Alfasayısal Katakana
- 1161 - Düşük Tonlu İşaretler ve Antik Karakterlerle Tayca euro ile (euro olmadan aynı: 874 )
- 1167 – KOI8-RU
- 1168 – KOI8-U
- 1300 - ANSI [PTS-DOS 6.70, 6.51 değil]
- 1370 - Geleneksel Çince MIX (Big5 kodlaması ) (1114 + 947 + euro) (euro olmadan aynı: 950 )
- 1380 - IBM-PC Basitleştirilmiş Çince GB PC-DATA (DBCS PC IBM GB 2312-80)
- 1381 - IBM-PC Basitleştirilmiş Çince (1115 + 1380 )
- 1393 - Japonca JIS X 0213 DBCS
- 1394 - IBM-PC Japonya (JIS X 0213) (897 + 1393 )
Daha eski donanım, protokoller ve dosya biçimleriyle uğraşırken, genellikle bu kod sayfalarını desteklemek gerekir, ancak daha yeni kodlama sistemleri, özellikle de Unicode, yeni tasarımlar için teşvik edilir.
DOS kod sayfaları genellikle .CPI dosyalarında saklanır.[15][16][17][18][19]
IBM AIX kod sayfaları
Bu kod sayfaları, IBM tarafından kendi AIX işletim sistemi. UNIX benzeri işletim sistemleri gibi ISO'ya göre kullanılmak üzere tasarlanmışlar gibi birkaç karakter kümesini taklit ederler.
- 367 - 7 bit US-ASCII
- 371 - 7 bit US-ASCII APL
- 806 - ISCII
- 813 – ISO 8859-7
- 819 – ISO 8859-1
- 895 - 7 bit Japon Latince
- 896 - 7-bit Japan Katakana Genişletilmiş
- 901 - Uzantısı ISO 8859-13 euro ile (euro olmadan aynı: 921 )
- 902 - Euro ile ISO Estonya (euro olmadan aynı: 922 )
- 912 - Uzantısı ISO 8859-2
- 913 – ISO 8859-3
- 914 – ISO 8859-4
- 915 - Uzantısı ISO 8859-5
- 916 – ISO 8859-8
- 919 – ISO 8859-10
- 920 – ISO 8859-9
- 921 - Uzantısı ISO 8859-13 (euro ile aynı: 901 )
- 922 - ISO Estonca (euro ile aynı: 902 )
- 923 – ISO 8859-15
- 952 - JIS X 0208 için EUC Japonca
- 953 - JIS X 0212 için EUC Japonca
- 954 - EUC Japonca (895 + 952 + 896 + 953 )
- 955 - TCP Japonca, JIS X 0208-1978
- 956 - TCP Japonca (895 + 952 + 896 + 953 )
- 957 - TCP Japonca (895 + 955 + 896 + 953 )
- 958 - TCP Japonca (367 + 952 + 896 + 953 )
- 959 - TCP Japonca (367 + 955 + 896 + 953 )
- 960 - Geleneksel Çin DBCS-EUC SICGCC Birincil Seti (1. düzlem)
- 961 - Geleneksel Çince DBCS-EUC SICGCC Tam Set + IBM Select + UDC
- 963 - Geleneksel Çince TCP, yalnızca CNS 11643 uçak 2
- 964 - EUC Geleneksel Çince (367 + 960 + 961 )
- 965 - TCP Geleneksel Çince (367 + 960 + 963 )
- 970 - EUC Korece (367 + 971 )
- 971 - EUC Kore DBCS (G1, KSC 5601 1989 (188 UDC dahil))
- 1006 - ISO 8 bit Urduca
- 1008 - ISO 8 bit Arapça
- 1009 - 7 bit ISO IRV
- 1010 - 7 bitlik Fransa
- 1011 - 7 bitlik Almanya F.R.
- 1012 - 7 bit İtalya
- 1013 - 7-bit Birleşik Krallık
- 1014 - 7 bit İspanya
- 1015 - 7 bit Portekiz
- 1016 - 7 bitlik Norveç
- 1017 - 7 bit Danimarka
- 1018 - 7 bit Finlandiya / İsveç
- 1019 - 7 bitlik Hollanda
- 1029 - Arapça Genişletilmiş
- 1036 - CCITT T.61
- 1089 – ISO 8859-6
- 1111 – ISO 8859-2
- 1124 - ISO Ukraynaca, benzer ISO 8859-5
- 1129 - ISO Vietnamca (euro ile aynı: 1163 )
- 1133 - ISO Lao
- 1163 - Euro ile ISO Vietnamca (euro olmadan aynı: 1129 )
- 1350 - EUC Japonca (JISeucJP) (367 + 952 + 896 + 953 )
- 1382 - EUC Basitleştirilmiş Çince (DBCS PC GB 2312-80)
- 1383 - EUC Basitleştirilmiş Çince (367 + 1382 )
Kod sayfası 819, Latin-1 ile aynıdır, ISO / IEC 8859-1 ve biraz değiştirilmiş komutlarla, MS-DOS makinelerinin bu kodlamayı kullanmasına izin verir. IBM AS / 400 mini bilgisayarlar ile kullanıldı.
IBM OS / 2 kod sayfaları
Bu kod sayfaları, IBM tarafından kendi OS / 2 işletim sistemi.
Windows öykünme kod sayfaları
Bu kod sayfaları, IBM tarafından Microsoft Windows karakter kümeleri. Bu kod sayfalarının çoğu, Microsoft kod sayfalarıyla aynı numaraya sahip olmalarına rağmen kesinlikle özdeş. Yine de bazı kod sayfaları, Microsoft tarafından tasarlanmayan IBM'den yenidir.
- 897 - IBM-PC SBCS Japonca (JIS X 0201-1976)
- 941 - Açık ortam için IBM-PC Japonca DBCS
- 947 - IBM-PC DBCS (Big5 kodlaması )
- 950 - Geleneksel Çince MIX (Big5 kodlaması ) (1114 + 947 ) (euro ile aynı: 1370 )
- 1114 - IBM-PC SBCS (Basitleştirilmiş Çince; GBK; Geleneksel çince; Big5 kodlaması )
- 1126 - IBM-PC Kore SBCS
- 1162 - Windows Tayca (Uzantı 874; ama yine de Windows'ta çağırdı)
- 1169 - Windows Kiril Asya
- 1174 - Windows Kazakça[21]
- 1250 - Pencereler Orta Avrupa
- 1251 - Pencereler Kiril
- 1252 - Pencereler Batı
- 1253 - Pencereler Yunan
- 1254 - Pencereler Türk
- 1255 - Pencereler İbranice
- 1256 - Pencereler Arapça
- 1257 - Pencereler Baltık
- 1258 - Pencereler Vietnam
- 1361 - Koreli (JOHAB )
- 1362 - Korece Hangul DBCS
- 1363 - Windows Korece (1126 + 1362 ) (Windows CP 949)
- 1372 - IBM-PC MS T Çince Big5 kodlaması (DB2'ye özel)
- 1373 - Windows Geleneksel Çince (uzantısı 950 )
- 1374 - IBM-PC DB Big5 kodlaması HKSCS uzantısı
- 1375 - Karışık Big5 kodlaması HKSCS uzantısı (eşleşmesi amaçlanmıştır) 950 )
- 1385 - IBM-PC Basitleştirilmiş Çince DBCS (GB18030 için Büyüyen CS, ayrıca GBK PC-DATA için de kullanılır.)
- 1386 - IBM-PC Basitleştirilmiş Çince GBK (1114 + 1385 ) (Windows CP 936)
- 1391 - Basitleştirilmiş Çince 4 Bayt (GB18030 için Büyüyen CS, ayrıca GBK PC-DATA için de kullanılır.)
- 1392 - IBM-PC Basitleştirilmiş Çince MIX (1252 + 1385 + 1391 )
Macintosh öykünme kod sayfaları
Bu kod sayfaları, IBM tarafından Apple'ı taklit ederken kullanılır. Macintosh karakter kümeleri.
Adobe emülasyon kodu sayfaları
Bu kod sayfaları, IBM tarafından Adobe karakter kümeleri.
HP öykünme kod sayfaları
Bu kod sayfaları, IBM tarafından HP karakter kümeleri.
- 1050 - HP Roman Uzantısı
- 1051 - HP Roman-8
- 1052 - HP Gothic Legal
- 1053 - HP Gothic-1 (neredeyse aynı ISO 8859-1 )
- 1054 - HP ASCII
- 1055 - HP PC Hattı
- 1056 - HP Çizgi Çekme
- 1057 - HP PC-8 (neredeyse aynı kod sayfası 437 )
- 1058 - HP PC-8DN (değil aynı kod sayfası 865 )
- 1351 - Japon DBCS HP karakter seti
- 5039 - Japonca MIX (1041 + 1351 )
DEC öykünme kod sayfaları
Bu kod sayfaları, IBM tarafından ARALIK karakter kümeleri.
- 1020 - 7-bit Kanada (Fransızca) NRC Seti
- 1021 - 7-bit İsviçre NRC Seti
- 1023 - 7-bit İspanyol NRC Seti
- 1090 - Özel Karakterler ve Çizgi Çizim Seti
- 1100 - Aralık Çokuluslu
- 1101 - 7 bit İngiliz NRC Seti
- 1102 - 7-bit Dutch NRC Seti
- 1103 - 7-bit Fin NRC Seti
- 1104 - 7-bit Fransız NRC Seti
- 1105 - 7-bit Norveççe / Danimarka NRC Seti
- 1106 - 7 bit İsveç NRC Seti
- 1107 - 7-bit Norveççe / Danimarka NRC Alternatifi
- 1287 - Aralık Yunanca
- 1288 - ARALIK Türkçe
IBM Unicode kod sayfaları
- 1200 – UTF-16BE Unicode (büyük adam ) IBM ile Özel Kullanım Alanı (PUA)[22]
- 1201 – UTF-16BE Unicode (büyük adam )[22]
- 1202 – UTF-16LE Unicode (küçük endian ) IBM PUA ile[22]
- 1203 – UTF-16LE Unicode (küçük endian )[22]
- 1208 – UTF-8 IBM PUA ile Unicode[22]
- 1209 – UTF-8 Unicode[22]
- 1400 - ISO 10646 UCS-BMP (Unicode 6.0'a göre)[22]
- 1401 - ISO 10646 UCS-SMP (Unicode 6.0'a göre)[22]
- 1402 - ISO 10646 UCS-SIP (Unicode 6.0'a göre)[22]
- 1414 - ISO 10646 UCS-SSP (Unicode 4.0'a göre)[22]
- 1445 - IBM AFP PUA No. 1
- 1446 - ISO 10646 UCS-PUP15 (Unicode 4.0'a göre)[22]
- 1447 - ISO 10646 UCS-PUP16 (Unicode 4.0'a göre)[22]
- 1448 - UCS-BMP (Genel UDC)
- 1449 - IBM varsayılan PUA
Microsoft kod sayfaları
Windows kod sayfaları
Bu kod sayfaları, Microsoft tarafından kendi Windows işletim sisteminde kullanılmaktadır. Microsoft tanımlı bir dizi kod sayfası ANSI kod sayfaları olarak bilinir (ilki olarak 1252, bir apokrif Neyin ANSI taslağı ISO 8859-1 ). Kod sayfası 1252, ISO 8859-1 üzerine inşa edilmiştir, ancak ek yazdırılabilir karakterler için C1 kontrol kodları yerine 0x80-0x9F aralığını kullanır. ISO 6429 ISO 8859-1 tarafından bahsedilmektedir.[23] Diğerlerinden bazıları kısmen diğer bölümlerine dayanmaktadır. ISO 8859 ancak genellikle 1252'ye yaklaştırmak için yeniden düzenlendi.
Microsoft, yeni uygulamaların bu kod sayfaları yerine UTF-8 veya UCS-2 / UTF-16 kullanmasını önerir.[24]
DBCS kod sayfaları
Bu kod sayfaları, DBCS çeşitli CJK dilleri için karakter kodlamaları. Microsoft işletim sistemlerinde, bunlar geçerli yerel ayar için hem "OEM" hem de "Windows" kod sayfası olarak kullanılır.
MS-DOS kod sayfaları
Bu kod sayfaları, Microsoft tarafından MS-DOS işletim sisteminde kullanılır. Microsoft bunları OEM kod sayfaları olarak adlandırır çünkü bunlar Orijinal ekipman üreticileri Microsoft veya bir standartlar kuruluşu tarafından değil, donanımlarıyla birlikte dağıtım için MS-DOS lisansı veren. Bu kod sayfalarının çoğu, eşdeğer IBM kod sayfalarıyla aynı numaraya sahip olmalarına rağmen kesinlikle özdeş. Minimum farklar var[25] IBM ve Microsoft'tan bazı kod sayfalarında.
- 708 - Arapça (ASMO 708)
- 709 - Arapça (ASMO 449+ / BCON V4)
- 710 - Arapça (Şeffaf Arapça)
- 720 - Arapça (Şeffaf ASMO)
- 737 – Yunan
- 850 - Latince-1
- 851 - Yunanca
- 852 - Latince-2
- 855 – Kiril
- 857 - Latince-5
- 858 - Latin-1 ile euro sembol
- 859 - Latince-9
- 860 – Portekizce
- 861 – İzlandaca
- 862 – İbranice
- 863 – Kanadalı Fransız
- 864 – Arapça
- 865 – Danimarka dili /Norveççe
- 866 - Belarusça, Rusça, Ukraynaca
- 869 – Yunan
Macintosh öykünme kod sayfaları
Bu kod sayfaları, Apple'ı taklit ederken Microsoft tarafından kullanılır. Macintosh karakter kümeleri.
- 10000 - Elma Macintosh Roman
- 10001 - Elma Japon
- 10002 - Apple Geleneksel Çince (Big5)
- 10003 - Apple Korece
- 10004 - Elma Arapça
- 10005 - Apple İbranice
- 10006 - Elma Yunan
- 10007 - Elma Macintosh Kiril
- 10008 - Apple Basitleştirilmiş Çince (GB 2312)
- 10010 - Elma Romence
- 10017 - Elma Ukrayna
- 10021 - Apple Thai
- 10029 - Elma Macintosh Orta Avrupa
- 10079 - Elma İzlandaca
- 10081 - Elma Türk
- 10082 - Elma Hırvat
Çeşitli diğer Microsoft kod sayfaları
Aşağıdaki kod sayfası numaraları Microsoft Windows'a özeldir. IBM, bu kod sayfaları için farklı numaralar kullanabilir. ISO'ya göre kullanılmak üzere tasarlanmışlar gibi birkaç karakter setini taklit ederler.[açıklama gerekli ] UNIX benzeri işletim sistemleri gibi.
- 20000 - Geleneksel Çince CNS
- 20001 - Geleneksel Çince TCA
- 20002 - Geleneksel Çin ETEN
- 20003 - Geleneksel Çince IBM5500
- 20004 - Geleneksel Çince TeleText
- 20005 - Geleneksel Çince Wang
- 20105 - 7 bit IA5 IRV[26][27][28]
- 20106 - 7 bit IA5 Almanca (DIN 66003)[26][27][29]
- 20107 - 7 bit IA5 İsveççe (SEN 850200 C)[26][27][30]
- 20108 - 7 bit IA5 Norveççe (NS 4551-2)[26][27][31]
- 20127 - 7 bit US-ASCII[26][27][32]
- 20261 – CCITT T.61
- 20269 – ISO 6937
- 20273
- 20277
- 20278
- 20284
- 20285
- 20290
- 20297
- 20420
- 20423
- 20424
- 20833
- 20838
- 20866 – KOI8-R
- 20871
- 20880 - EBCDIC Kiril (880)
- 20905
- 20924
- 20932
- 20936
- 20949
- 21025 - EBCDIC Kiril (1025)
- 21027
- 21866 – KOI8-U
- 28591 – ISO-8859-1
- 28592 – ISO-8859-2
- 28593 – ISO-8859-3
- 28594 – ISO-8859-4
- 28595 – ISO-8859-5
- 28596 – ISO-8859-6
- 28597 – ISO-8859-7
- 28598 – ISO-8859-8
- 28599 – ISO-8859-9
- 28600 – ISO-8859-10
- 28601 – ISO-8859-11
- 28602 - kullanılmıyor (ayrılmıştır ISO-8859-12 )
- 28603 – ISO-8859-13
- 28604 – ISO-8859-14
- 28605 – ISO-8859-15
- 28606 – ISO-8859-16
- 38596 – ISO-8859-6
- 38598 – ISO-8859-8
Microsoft Unicode kod sayfaları
- 1200 – UTF-16LE Unicode (küçük endian )
- 1201 – UTF-16BE Unicode (büyük adam )
- 12000 – UTF-32LE Unicode (küçük endian )
- 12001 – UTF-32BE Unicode (büyük adam )
- 65000 – UTF-7 Unicode
- 65001 – UTF-8 Unicode
- 65520 - Boş Unicode Düzlemi
HP Sembol Setleri
HP, kendi karakter kümelerini veya diğer satıcıların karakter kümelerini kodlamak için bir dizi Simge Kümesi (her biri ilişkili Simge Kümesi Koduna sahip) geliştirdi. Normalde, bir üst kısma taşındığında ve ASCII karakter setiyle ilişkilendirildiğinde 8 bitlik karakter kümeleri oluşturan 7 bitlik karakter kümeleridir.
HP kendi Sembol Kümeleri
- Sembol Seti 0E - HP Roman Uzantısı - aksanlı harflerle 7 bitlik karakter seti (IBM tarafından kod sayfası 1050 )
- Sembol Seti 0G - HP 7-bit Almanca
- Sembol Seti 0L - HP Line Draw (IBM tarafından şu şekilde kodlanmıştır: kod sayfası 1056 )
- Sembol Seti 0M - HP Math-7
- Sembol Seti 0T - HP Thai-8
- Sembol Seti 1S - HP 7-bit İspanyolca
- Sembol Seti 1U - HP 7-bit Gothic Legal (IBM tarafından şu şekilde kodlanmıştır: kod sayfası 1052 )
- Sembol Seti 4Q - 7 bitlik PC Hattı (IBM tarafından şu şekilde kodlanmıştır: kod sayfası 1055 )
- Sembol Seti 4U - HP Roman-9 - Roma - 8 + €
- Sembol Seti 7J - HP Masaüstü
- Sembol Seti 7S - HP 7-bit Avrupa İspanyolcası
- Sembol Seti 8E - HP East-8
- Sembol Seti 8G - HP Greek-8 (IR 088'e göre; ELOT 927'ye göre değil)
- Sembol Seti 8H - HP Hebrew-8
- Sembol Seti 8I - MS LineDraw (ASCII + HP PC Line)
- Sembol Seti 8K - HP Kana-8 (ASCII + Japon Katakana)
- Sembol Seti 8L - HP LineDraw (ASCII + HP Line Draw)
- Sembol Seti 8M - HP Math-8 (ASCII + HP Math-8)
- Sembol Seti 8R - HP Kiril-8
- Sembol Seti 8S - HP 7-bit Latin Amerika İspanyolcası
- Sembol Seti 8T - HP Turkish-8
- Sembol Seti 8U - HP Roman-8 (ASCII + HP Roman Extension; IBM tarafından şu şekilde kodlanmıştır: kod sayfası 1051 )
- Sembol Seti 8V - HP Arabic-8
- Sembol Seti 9K - HP Kore-8
- Sembol Seti 9T - PC 8T (Kod Sayfası 437-T olarak da bilinir; bu, değil kod sayfası 857 )
- Sembol Seti 9V - Windows için Latince / Arapça (bu, değil kod sayfası 1256 )
- Sembol Seti 11U - PC 8D / N (Kod Sayfası 437-N olarak da bilinir; IBM tarafından şu şekilde kodlanır: kod sayfası 1058; bu değil kod sayfası 865 )
- Sembol seti 14G - PC-8 Yunanca Alternatif (Kod Sayfası 437-G olarak da bilinir; hemen hemen aynı kod sayfası 737 )
- Sembol Seti 18K -
- Sembol Seti 18T -
- Sembol Seti 19C -
- Sembol Seti 19K -
Diğer satıcılardan Sembol Setleri
- Sembol Seti 0D - ISO 60: 7-bit Norveççe
- Sembol Seti 0F - ISO 25: 7-bit Fransızca
- Sembol Seti 0H - HP 7-bit İbranice - Neredeyse İsrail Standardı ile aynı SI 960
- Sembol Seti 0I - ISO 15: 7-bit İtalyanca
- Sembol Seti 0K - ISO 14: 7-bit Japon Katakana
- Sembol Seti 0N - ISO 8859-1 Latin 1 (Başlangıçta "Gothic-1" olarak adlandırılır; IBM tarafından kod sayfası 1052 olarak kodlanmıştır)
- Sembol Seti 0R - ISO 8859-5 Latin / Kiril (1986 sürümü - IR 111)
- Sembol Seti 0S - ISO 11: 7-bit İsveççe
- Sembol Seti 0U - ISO 6: 7-bit U.S.
- Sembol Seti 0V - Arapça
- Sembol Seti 1D - ISO 61: 7-bit Norveççe
- Sembol Seti 1E - ISO 4: 7-bit U. K.
- Sembol Seti 1F - ISO 69: 7-bit Fransızca
- Sembol Seti 1G - ISO 21: 7-bit Almanca
- Sembol Seti 1K - ISO 13: 7-bit Japonca Latince
- Sembol Seti 1T - Windows Tay Dili (Pratik olarak aynı 874 )
- Sembol Seti 2K - ISO 57: 7-bit Basitleştirilmiş Çince Latince
- Sembol Seti 2N - ISO 8859-2 Latin 2
- Sembol Seti 2S - ISO 17: 7-bit İspanyolca
- Sembol Seti 2U - ISO 2: 7 bit Uluslararası Saygı Sürümü
- Sembol Seti 3N - ISO 8859-3 Latin 3
- Sembol Seti 3R - PC-866 Rusya (Hemen hemen aynı kod sayfası 866 )
- Sembol Seti 3S - ISO 10: 7-bit İsveççe
- Sembol Seti 4N - ISO 8859-4 Latin 4
- Sembol Seti 4S - ISO 16: 7-bit Portekizce
- Sembol Seti 5M - PS Matematik Sembolü (Hemen hemen aynı Adobe Sembolleri )
- Sembol Seti 5N - ISO 8859-9 Latin 5
- Sembol Seti 5S - ISO 84: 7-bit Portekizce
- Simge Seti 5T - Windows 3.1 Latin-5 (Hemen hemen aynı kod sayfası 1254 )
- Sembol Seti 6J - Microsoft Publishing
- Sembol Seti 6M - Ventura Math
- Sembol Seti 6N - ISO 8859-10 Latin 6
- Sembol Seti 6S - ISO 85: 7-bit İspanyolca
- Sembol Seti 7H - ISO 8859-8 Latin / İbranice
- Sembol Seti 9E - Windows 3.1 Latin 2 (Hemen hemen aynı kod sayfası 1250 )
- Sembol Seti 9G - Windows 98 Yunanca (Hemen hemen aynı kod sayfası 1253 )
- Sembol Seti 9J - PC 1004
- Sembol Seti 9L - Ventura ITC Zapf Dingbats
- Sembol Seti 9N - ISO 8859-15 Latin 9
- Sembol Seti 9R - Windows 98 Kiril (Hemen hemen aynı kod sayfası 1251 )
- Sembol Seti 9U - Windows 3.0
- Sembol Seti 10G - PC-851 Latin / Yunanca (Hemen hemen aynı kod sayfası 851 )
- Sembol Seti 10J - PS Metni (Hemen hemen aynı Adobe Standard )
- Sembol Seti 10L - PS ITC Zapf Dingbats (Pratik olarak aynı Adobe Dingbats )
- Sembol Seti 10N - ISO 8859-5 Latin / Kiril (1988 sürümü - IR 144)
- Sembol Seti 10R - PC-855 Kiril (Hemen hemen aynı kod sayfası 855 )
- Sembol Seti 10T - Teleteks
- Sembol Seti 10U - PC-8 (Pratik olarak aynı kod sayfası 437; IBM tarafından şu şekilde kodlanmıştır: kod sayfası 1057 )
- Sembol Seti 10V - CP-864 (Hemen hemen aynı kod sayfası 864 )
- Sembol Seti 11G - CP-869 (Hemen hemen aynı kod sayfası 869 )
- Sembol Seti 11J - PS ISO Latin-1 (Hemen hemen aynı Adobe Latin-1 )
- Sembol Seti 11N - ISO 8859-6 Latin / Arapça
- Sembol Seti 12G - PC Latince / Yunanca (Hemen hemen aynı kod sayfası 737 )
- Sembol Seti 12J - MC Metni (Hemen hemen aynı Macintosh Roman )
- Sembol Seti 12N - ISO 8859-7 Latince / Yunanca
- Sembol Seti 12R - PC Gost (Hemen hemen aynı PC GOST Ana )
- Sembol Seti 12U - PC-850 Latin 1 (Hemen hemen aynı kod sayfası 850 )
- Sembol Seti 13J - Ventura International
- Sembol Seti 13R - PC Bulgarca (Hemen hemen aynı MIK )
- Sembol Seti 13U - PC-858 Latin 1 + € (Hemen hemen aynı kod sayfası 858 )
- Sembol Seti 14J - Ventura U. S.
- Sembol Seti 14L - Windows Dingbats
- Sembol Seti 14P - ABICOMP International (Hemen hemen aynı ABICOMP )
- Sembol Seti 14R - PC Ukraynaca (Hemen hemen aynı RUSCII )
- Sembol Seti 15H - PC-862 İsrail (Hemen hemen aynı kod sayfası 862 )
- Sembol Seti 16U - PC-857 Latin 5 (Hemen hemen aynı kod sayfası 857 )
- Sembol Seti 17U - PC-852 Latin 2 (Hemen hemen aynı kod sayfası 852 )
- Sembol Seti 18N - UTF-8
- Sembol Seti 18U - PC-853 Latin 3 (Hemen hemen aynı kod sayfası 853 )
- Sembol Seti 19L - Windows 98 Baltic (Hemen hemen aynı kod sayfası 1257 )
- Sembol Seti 19M - Windows Sembolü
- Sembol Seti 19U - Windows 3.1 Latin 1 (Hemen hemen aynı kod sayfası 1252 )
- Symbol Set 20U — PC-860 Portugal (Practically the same as code page 860 )
- Symbol Set 21U — PC-861 Iceland (Practically the same as code page 861 )
- Symbol Set 23U — PC-863 Canada - French (Practically the same as code page 863 )
- Symbol Set 24Q — PC-Polish Mazowia (Practically the same as Mazovia kodlaması )
- Symbol Set 25U — PC-865 Denmark/Norway (Practically the same as code page 865 )
- Symbol Set 26U — PC-775 Latin 7 (Practically the same as kod sayfası 775 )
- Symbol Set 27Q — PC-8 PC Nova (Practically the same as PC Nova )
- Symbol Set 27U — PC Latvian Russian (also known as 866-Latvian)
- Symbol Set 28U — PC Lithuanian/Russian (Practically the same as code page 774 )
- Symbol Set 29U — PC-772 Lithuanian/Russian (Practically the same as code page 772 )
Code pages from other vendors
These code pages are independent assignments by third party vendors. Since the original IBM PC code page (number 437 ) was not really designed for international use, several partially compatible country or region specific variants emerged.
These code pages number assignments are not official neither by IBM, neither by Microsoft and almost none of them is referred as a usable character set by IANA. The numbers assigned to these code pages are arbitrary and may clash to registered numbers in use by IBM or Microsoft. Some of them may predate codepage switching being added in DOS 3.3.
- 100 – DOS Hebrew hardware fontpage (Not from IBM; HDOS )[33]
- 111 – DOS Greek (Not from IBM; AST Premium Exec DOS 5.0[34][35][36])
- 112 – DOS Turkish (Not from IBM; AST Premium Exec DOS 5.0[34][35][36])
- 113 – DOS Yugoslavian (Not from IBM; AST Premium Exec DOS 5.0[34][35][36])
- 151 – DOS Nafitha Arabic (Not from IBM; ADOS )
- 152 – DOS Nafitha Arabic (Not from IBM; ADOS )
- 161 – DOS Arapça (Not from IBM; ADOS )[33]
- 162 – DOS Arabic (Not from IBM; ADOS)
- 163 – DOS Arabic (Not from IBM; ADOS)[33]
- 164 – DOS Arabic (Not from IBM; ADOS)
- 165 – DOS Arabic (Not from IBM; ADOS)[33]
- 166 – IBM Arabic PC (ADOS)[33]
- 210 – DEC DOS Greek (NEC Jetmate printers)
- 220 – DEC DOS Spanish (Not from IBM)
- 489 – Czechoslovakian [OCR software 1993]
- 620 – DOS Polish (Mazovia) (Not from IBM)
- 667 – DOS Polish (Mazovia) (Not from IBM)
- 668 – DOS Polish (Not from IBM)
- 707 – MS-DOS Arabic Sakhr (Not from IBM; Sakhr Software itibaren MSX Computers)
- 711 – MS-DOS Arabic Nafitha Enhanced (Not from IBM)
- 714 – MS-DOS Arabic Sakr (Not from IBM)
- 715 – MS-DOS Arabic APTEC (Not from IBM)
- 721 – MS-DOS Arabic Nafitha International (Not from IBM)
- 768 – Arabic Al-Arabi (Not from IBM)
- 770 – DOS Estonian, Latvian, Lithuanian[37] (From Lithuanian Lika Software;[38] Lithuanian RST 1095-89 National Standard)
- 771 – DOS Lithuanian/Cyrillic — KBL[39] (From Lithuanian Lika Software[38])
- 772 – DOS Lithuanian/Cyrillic[40] (From Lithuanian Lika Software;[38] Lithuanian LST 1284:1993 National Standard; adopted by IBM as code page 1119 )
- 773 – DOS Latin-7 — KBL (From Lithuanian Lika Software)
- 774 – DOS Lithuanian[41] (From Lithuanian Lika Software;[38] Lithuanian LST 1283:1993 National Standard; adopted by IBM as code page 1118 )
- 775 – DOS Latin-7 Baltic Rim (From Lithuanian Lika Software;[38] Lithuanian LST 1590-1 National Standard; adopted by IBM and Microsoft as kod sayfası 775 )
- 776 – DOS Lithuanian (extended CP770)[42] (From Lithuanian Lika Software[38])
- 777 – DOS Accented Lithuanian (old) (extended CP773) — KBL[42] (From Lithuanian Lika Software[38])
- 778 – DOS Accented Lithuanian (extended CP775)[42] (From Lithuanian Lika Software[38])
- 790 – DOS Polish (Mazovia)
- 854 – Spanish[43][6]
- 881 – Latin 1 (Not from IBM; AST Premium Exec DOS 5.0[34][35][36]) (conflictive ID with IBM EBCDIC 881 )
- 882 – Latin 2 (ISO 8859-2) (Not from IBM; same as Code page 912; AST Premium Exec DOS 5.0[34][35][36]) (conflictive ID with IBM EBCDIC 882 )
- 883 – Latin 3 (Not from IBM; AST Premium Exec DOS 5.0[34][35][36]) (conflictive ID with IBM EBCDIC 883 )
- 884 – Latin 4 (Not from IBM; AST Premium Exec DOS 5.0[34][35][36]) (conflictive ID with IBM EBCDIC 884 )
- 885 – Latin 5 (Not from IBM; AST Premium Exec DOS 5.0[34][35][36]) (conflictive ID with IBM EBCDIC 885 )
- 895 – Czech (Kamenický), (Not from IBM; conflictive ID with IBM CP895 — 7-bit EUC Japanese Roman)
- 896 – DOS Polish (Mazovia) (Not from IBM; conflictive ID with IBM CP896 — 7-bit EUC Japanese Katakana)
- 900 – DOS Russian (Russian MS-DOS 5.0 LCD.CPI)
- 928 – Greek (on Star[44] printers); same as Greek National Standard ELOT 928 (Not from IBM; conflictive ID with IBM CP928 — Simplified Chinese PC DBCS)
- 966 – Saudi Arabian (Not from IBM)
- 991 – DOS Polish (Mazovia) (Not from IBM)
- 999 – DOS Serbo-Croatian I (Not from IBM); also known as PC Nova and CroSCII; lower part is JUSI.B1.002, upper part is code page 437; destekler Slovence ve Sırp-Hırvat (Latin script)
- 1001 – Arabic (on Star[44] printers) (Not from IBM; conflictive ID with IBM CP1001 — MICR)
- 1261 – Windows Korean IBM-1261 LMBCS-17, similar to 1363
- 1270 – Windows Sámi
- 2001 – Lithuanian KBL (on Star[44] printers); same as code page 771
- 3001 – Estonian 1 (on Star[44] printers); same as code page 1116
- 3002 – Estonian 2 (on Star[44] printers); same as code page 922
- 3011 – Latvian 1 (on Star[44] printers); same as code page 437-Latvian
- 3012 – Latvian-2 (on Star[44] printers); same as code page 866-Latvian (Latvian RST 1040-90 National Standard)
- 3021 – Bulgarian (on Star[44] printers); same as MIK
- 3031 – Hebrew (on Star[44] printers); same as code page 862
- 3041 – Maltese (on Star[44] printers); ile aynı ISO 646 Malta dili
- 3840 – IBM-Russian (on Star[44] printers); nearly the same as CP 866
- 3841 – Gost-Russian (on Star[44] printers); GOST 13052 plus characters for Central Asian languages
- 3843 – Polish (on Star[44] printers); same as Mazovia
- 3844 – CS2 (on Star[44] printers); same as Kamenický
- 3845 – Hungarian (on Star[44] printers); same as CWI
- 3846 – Turkish (on Star[44] printers); same as PC-8 Turkish + old Turkish Lira sign (Tʟ) at code point A8
- 3847 – Brazil-ABNT (on Star[44] printers); same as the Brazilian National Standard NBR-9614:1986
- 3848 – Brazil-ABICOMP (on Star[44] printers); same as ABICOMP
- 3850 – Standard KU (on Star[44] printers); variation of the Kasetsart University encoding for Thai
- 3860 – Rajvitee KU (on Star[44] printers); variation of the Kasetsart University encoding for Thai
- 3861 – Microwiz KU (on Star[44] printers); variation of the Kasetsart University encoding for Thai
- 3863 – STD988 TIS (on Star[44] printers); variation of the TIS 620 encoding for Thai
- 3864 – Popular TIS (on Star[44] printers); variation of the TIS 620 encoding for Thai
- 3865 – Newsic TIS (on Star[44] printers); variation of the TIS 620 encoding for Thai
- (number missing) – CWI-2 (for DOS) supports Macarca
- (number missing) – MIK (for DOS) supports Bulgarca
- (number missing) – DOS Serbo-Croatian II; destekler Slovence ve Sırp-Hırvat (Latin script)
- (number missing) — Russian Alternative code page (for DOS); this is the origin for IBM CP 866
List of code page assignments
List of known code page assignments (incomplete):
| İD | İsimler | Açıklama | Menşei | Platform | DOS | OS / 2 | pencereler | Mac | Başka | Kodlama | Yorum Yap |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Yok | Ayrılmış | IBM, Microsoft | Yok | 3.3+ | 1.0+ | ? | ? | ? | Internal OS use[33] | |
| 437 | CP437, IBM437 | PC US | IBM[45] | IBM PC | 3.3+ | 1.0+ | Evet | ? | Evet | 8 bit SBCS | |
| 57344 - 61439 | Yok | Private use derivations | IBM | Yok | Yok | Yok | Yok | Yok | Yok | çeşitli | Private use code page derivations (E000h-EFFFh) |
| 65280 - 65533 | Yok | Private use definitions | IBM | Yok | Yok | Yok | Yok | Yok | Yok | çeşitli | Private use code page definitions (FF00h-FFFDh) |
| 65534 | Yok | Ayrılmış | IBM, Microsoft | Yok | ? | ? | ? | ? | ? | çeşitli | Internal OS use (FFFEh) |
| 65535 | Yok | Ayrılmış | IBM, Microsoft | Yok | 3.3+ | 1.0+ | ? | ? | ? | çeşitli | Internal OS use (FFFFh)[33] |
Eleştiri
Many older character encodings (unlike Unicode) suffer from several problems. Some code page vendors insufficiently document the meaning of all code point values, which decreases the reliability of handling textual data through various computer systems consistently. Some vendors add proprietary extensions to some code pages to add or change certain code point values; for example, byte 0x5C in Shift JIS can represent either a back slash or a yen para birimi simgesi depending on the platform. Finally, in order to support several languages in a program that does not use Unicode, the code page used for each string/document needs to be stored.
Due to Unicode's extensive documentation, vast repertoire of characters and stability policy of characters, the problems listed above are rarely a concern for Unicode. Applications may also mislabel text in Windows-1252 gibi ISO-8859-1. Fortunately, the only difference between these code pages is that the code point values used by ISO-8859-1 for control characters are instead used as additional printable characters in Windows-1252. Since control characters have no function in HTML, web browsers tend to use Windows-1252 rather than ISO-8859-1. In HTML5, treating ISO-8859-1 as Windows-1252 is even codified as standard. Later, UTF-8 has succeeded both encodings in terms of popularity on the Internet.[46][47]
Private code pages
When, early in the history of personal computers, users did not find their character encoding requirements met, private or local code pages were created using Terminate and Stay Resident utilities or by re-programming BIOS EPROM'lar. In some cases, unofficial code page numbers were invented (e.g. CP895).
When more diverse character set support became available most of those code pages fell into disuse, with some exceptions such as the Kamenický or KEYBCS2 encoding for the Çek ve Slovak alfabe. Another character set is Iran System encoding standard that was created by Iran System corporation for Farsça dili destek. This standard was in use in Iran in DOS-based programs and after introduction of Microsoft code page 1256 this standard became obsolete. However some Windows and DOS programs using this encoding are still in use and some Windows fonts with this encoding exist.
In order to overcome such problems, the IBM Character Data Representation Architecture level 2 specifically reserves ranges of code page IDs for user-definable and private-use assignments. Whenever such code page IDs are used, the user must not assume that the same functionality and appearance can be reproduced in another system configuration or on another device or system unless the user takes care of this specifically.The code page range 57344-61439 (E000h-EFFFh) is officially reserved for user-definable code pages (or actually CCSIDs in the context of IBM CDRA ), whereas the range 65280-65533 (FF00h-FFFDh) is reserved for any user-definable "private use" assignments.For example, a non-registered custom variant of code page 437 (1B5h) or 28591 (6FAF) could become 57781 (E1B5h) or 61359 (EFAFh), respectively, in order to avoid potential conflicts with other assignments and maintain the sometimes existing internal numerical logic in the assignments of the original code pages. An unregistered private code page not based on an existing code page, a device specific code page like a printer font, which just needs a logical handle to become addressable for the system, a frequently changing download font, or a code page number with a symbolic meaning in the local environment could have an assignment in the private range like 65280 (FF00h).
The code page IDs 0, 65534 (FFFEh) and 65535 (FFFFh) are reserved for internal use by operating systems such as DOS and must not be assigned to any specific code pages.
Ayrıca bakınız
- Windows kod sayfası
- Karakter kodlaması
- CCSID IBM's official "code page" definitions and assignments
- Codepage sniffing
- Unicode
Referanslar
- ^ IBM i Globalization - EBCDIC Code Pages
- ^ "Code Page". sap.com.
- ^ a b "Sözlük". oracle.com.
- ^ "VT510 Video Terminal Programmer Information". Digital Equipment Corporation (Aralık). 7.1. Character Sets - Overview. Alındı 2017-02-15.
Geleneksele ek olarak ARALIK ve ISO character sets, which conform to the structure and rules of ISO 2022, VT510 supports a number of IBM PC code pages (sayfa numaraları in IBM's standard character set manual) in PCTerm mode to emulate the console terminal of industry-standard PCs.
- ^ "7.1. Character Sets - Overview". VT520/VT525 Video Terminal Programmer Information (PDF). Digital Equipment Corporation (Aralık). Temmuz 1994. s. 7-1. EK-VT520-RM. A01. Arşivlendi (PDF) 2017-02-15 tarihinde orjinalinden. Alındı 2017-02-15.
Geleneksele ek olarak ARALIK ve ISO character sets the VT520 supports a number of IBM PC code pages (which refer to sayfa numaraları in IBM's standard character set manual) in PCTerm mode to emulate the console terminal of industry-standard PCs.
- ^ a b c Paul, Matthias R. (2001-06-10) [1995]. "Overview on DOS, OS/2, and Windows codepages" (CODEPAGE.LST file) (1.59 preliminary ed.). Arşivlendi from the original on 2016-04-20. Alındı 2016-08-20.
- ^ Printer Command Language Symbol Sets
- ^ HP Symbol Sets
- ^ PCL5 Camparison Guide
- ^ Zbikowski, Mark; Allen, Paul; Ballmer, Steve; Borman, Reuben; Borman, Rob; Butler, John; Carroll, Chuck; Chamberlain, Mark; Chell, David; Colee, Mike; Courtney, Mike; Dryfoos, Mike; Duncan, Rachel; Eckhardt, Kurt; Evans, Eric; Çiftçi, Rick; Gates, Bill; Geary, Michael; Griffin, Bob; Hogarth, Doug; Johnson, James W .; Kermaani, Kaamel; Kral Adrian; Koch, Reed; Landowski, James; Larson, Chris; Lennon, Thomas; Lipkie, Dan; McDonald, Marc; McKinney, Bruce; Martin, Pascal; Mathers, Estelle; Matthews, Bob; Melin, David; Mergentime, Charles; Nevin, Randy; Newell, Dan; Newell, Tani; Norris, David; O'Leary, Mike; O'Rear, Bob; Olsson, Mike; Osterman, Larry; Ostling, Sırt; Pai, Sunil; Paterson, Tim; Perez, Gary; Peters, Chris; Petzold, Charles; Pollock, John; Reynolds, Aaron; Rubin, Darryl; Ryan, Ralph; Schulmeisters, Karl; Shah, Rajen; Shaw, Barry; Kısa, Anthony; Slivka, Ben; Smirl, Jon; Stillmaker, Betty; Stoddard, John; Tillman, Dennis; Whitten, Greg; Yount, Natalie; Zeck Steve (1988). "Teknik danışmanlar". MS-DOS Ansiklopedisi: 1.0 - 3.2 arası sürümler. Duncan, Ray tarafından; Bostwick, Steve; Burgoyne, Keith; Byers, Robert A .; Hogan, Thom; Kyle, Jim; Letwin, Gordon; Petzold, Charles; Rabinowitz, Chip; Tomlin, Jim; Wilton, Richard; Wolverton, Van; Wong, William; Woodcock, JoAnne (Tamamen elden geçirilmiş ed.). Redmond, Washington, ABD: Microsoft Press. ISBN 1-55615-049-0. LCCN 87-21452. OCLC 16581341. [1] (xix+1570 pages; 26 cm) (NB. This edition was published in 1988 after extensive rework of the withdrawn 1986 first edition by a different team of authors.)
- ^ "Kod Sayfası Tanımlayıcıları". microsoft.com. Microsoft.
- ^ "VGA/SVGA Video Programming--VGA Text Mode Operation". osdever.net.
- ^ a b c d e f xlate - Transliterate Contents of Records, IBM Corporation, 2010 [1986], alındı 2016-10-18
- ^ "Code Page CPGID 01093 (pdf)" (PDF). Arşivlenen orijinal (PDF) 2015-07-08 tarihinde.
- ^ Paul, Matthias R. (2001-06-10) [1995]. "Format description of DOS, OS/2, and Windows NT .CPI, and Linux .CP files" (CPI.LST file) (1.30 ed.). Arşivlendi from the original on 2016-04-20. Alındı 2016-08-20.
- ^ Elliott, John C. (2006-10-14). "CPI file format". Seasip.info. Arşivlendi 2016-09-22 tarihinde orjinalinden. Alındı 2016-09-22.
- ^ Brouwer, Andries Evert (2001-02-10). "CPI fonts". 0.2. Arşivlendi 2016-09-22 tarihinde orjinalinden. Alındı 2016-09-22.
- ^ Haralambous, Yannis (Eylül 2007). Fonts & Encodings. Translated by Horne, P. Scott (1 ed.). Sebastopol, California, USA: O'Reilly Media, Inc. pp. 601–602, 611. ISBN 978-0-596-10242-5.
- ^ MS-DOS Programmer's Reference. Microsoft Press. 1991. ISBN 1-55615-329-5.
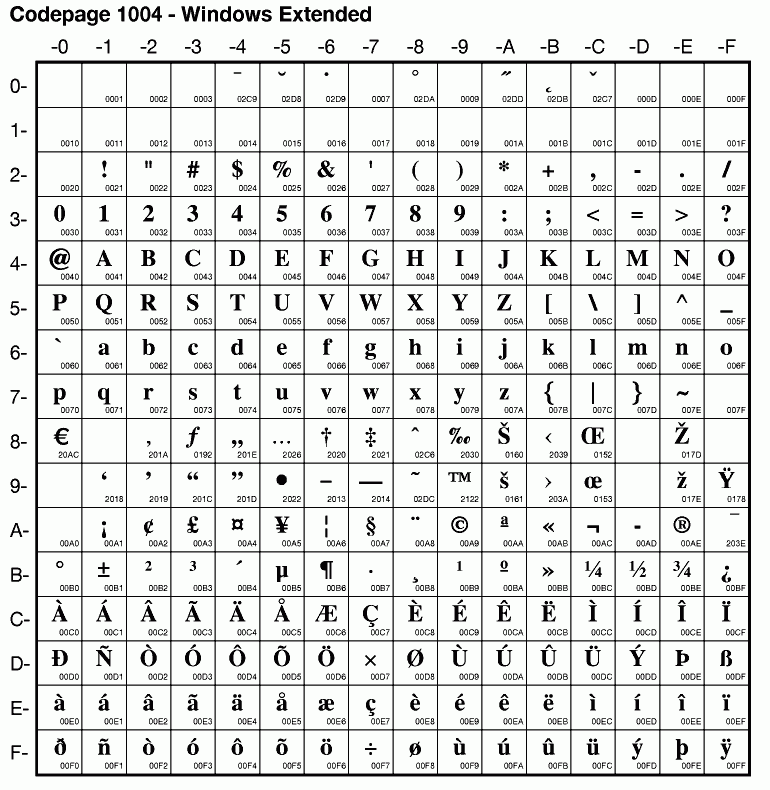
- ^ "Codepage 1004 - Windows Extended". IBM. 2001. Arşivlendi 2018-05-13 tarihinde orjinalinden. Alındı 2018-05-13.
- ^ "Character Data Representation Architecture".
- ^ a b c d e f g h ben j k l "IBM Coded Character Set Identifier (CCSID)". IBM. Arşivlenen orijinal 2009-11-26.
- ^ ISO/IEC 8859-1:1998(E). ISO. 1998-04-15. s. 1.
The coded characters in this set may be used in conjunction with coded control functions selected from ISO/IEC 6429.
- ^ "Code Pages". microsoft.com. Microsoft.
- ^ [2]
- ^ a b c d e "Kod Sayfası Tanımlayıcıları". Microsoft Geliştirici Ağı. Microsoft. 2014. Arşivlendi 2016-06-19 tarihinde orjinalinden. Alındı 2016-06-19.
- ^ a b c d e "Web Kodlamaları - Internet Explorer - Kodlamalar". WHATWG Wiki. 2012-10-23. Arşivlendi 2016-06-20 tarihinde orjinalinden. Alındı 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "Batı Avrupa (IA5) kodlaması - Windows karakter kümeleri". WUtils.com - Çevrimiçi web yardımcı programı ve yardım. Motobit Yazılımı. Arşivlendi 2016-06-20 tarihinde orjinalinden. Alındı 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "Almanca (IA5) kodlaması - Windows karakter kümeleri". WUtils.com - Çevrimiçi web yardımcı programı ve yardım. Motobit Yazılımı. Arşivlendi 2016-06-20 tarihinde orjinalinden. Alındı 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "İsveççe (IA5) kodlaması - Windows karakter kümeleri". WUtils.com - Çevrimiçi web yardımcı programı ve yardım. Motobit Yazılımı. Arşivlendi 2016-06-20 tarihinde orjinalinden. Alındı 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "Norveç (IA5) kodlaması - Windows karakter kümeleri". WUtils.com - Çevrimiçi web yardımcı programı ve yardım. Motobit Yazılımı. Arşivlendi 2016-06-20 tarihinde orjinalinden. Alındı 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "US-ASCII kodlaması - Windows karakter kümeleri". WUtils.com - Çevrimiçi web yardımcı programı ve yardım. Motobit Yazılımı. Arşivlendi 2016-06-20 tarihinde orjinalinden. Alındı 2016-06-20.
- ^ a b c d e f g Paul, Matthias R. (2002-09-05), Technical info on undocumented DOS country info for LCASE, ARAMODE and CCTORC records, FreeDOS development list fd-dev at Topica, archived from orijinal 2016-05-27 tarihinde, alındı 2016-05-26
- ^ a b c d e f g h Kahverengi, Ralf D. (2002-12-29). X86 Kesinti Listesi. 61.
- ^ a b c d e f g h Paul, Matthias R. (1997-07-30). NWDOS-TIPs - İpuçları ve Püf Noktaları rund um Novell DOS 7, mit Blick auf undokumentierte Ayrıntılar, Hatalar ve Geçici Çözümler. MPDOSTIP. Sürüm 157 (Almanca) (3 ed.). Arşivlenen orijinal 2016-05-22 tarihinde. Alındı 2012-01-11. (NB. NWDOSTIP.TXT, Novell DOS 7 ve OpenDOS 7.01 birçok belgelenmemiş özelliğin ve dahili öğenin açıklaması dahil. Yazarın daha büyük MPDOSTIP.ZIP koleksiyonunun bir parçasıdır ve 2001 yılına kadar korunmuştur ve o sırada birçok sitede dağıtılmıştır. Sağlanan bağlantı, NWDOSTIP.TXT dosyasının HTML ile dönüştürülmüş eski bir sürümüne işaret ediyor.)
- ^ a b c d e f g h Paul, Matthias R. (2001-04-09). NWDOS-TIPs - İpuçları ve Püf Noktaları rund um Novell DOS 7, mit Blick auf undokumentierte Ayrıntılar, Hatalar ve Geçici Çözümler. MPDOSTIP. Release 183 (in German) (3 ed.).
- ^ "770". From Lithuanian Lika Software
- ^ a b c d e f g h Changed its name to "Likit". Went out of business?
- ^ "771". From Lithuanian Lika Software
- ^ "772". From Lithuanian Lika Software
- ^ "774". From Lithuanian Lika Software
- ^ a b c "lietuvybė.lt - Rašmenų koduotės" [lietuvybė.lt - Character encodings] (in Lithuanian).
- ^ Hogan, Thom (1992). Die PC-Referenz für Programmierer (in German) (2 ed.). Systhema Verlag GmbH. ISBN 3-89390-272-4. (NB. This book is the German translation of "The Programmer's PC Sourcebook" by Microsoft Press. It mentions the code page ID 854 for Spain.)
- ^ a b c d e f g h ben j k l m n Ö p q r s t sen v w x "Star LC 8021 User's Manual" (PDF).
- ^ IBM. "SBCS code page information document - CPGID 00437". Alındı 2014-07-04.
- ^ "Usage Statistics of Character Encodings for Websites, (updated daily)". w3techs.com. Alındı 2015-08-06.
- ^ "UTF-8 Usage Statistics". Trendler.builtwith.com. Alındı 2011-03-28.
{kind=link}
{kind=link}
Dış bağlantılar
- IBM CDRA glossary
- IBM code pages -de Wayback Makinesi (archived 2016-02-05)
- IBM code pages by encoding scheme -de Wayback Makinesi (archived 2009-09-06)
- IBM/ICU Charset Information
- Microsoft Code Page Identifiers (Microsoft's list contains only code pages actively used by normal apps on Windows. See also Torsten Mohrin's list for the full list of supported code pages)
- Shorter Microsoft list containing only the ANSI and OEM code pages but with links to more detail on each -de Wayback Makinesi (archived 2012-10-23)
- Character Sets And Code Pages At The Push Of A Button
- Microsoft Chcp command: Display and set the console active code page