Needleman-Wunsch algoritması - Needleman–Wunsch algorithm
Bu makale çoğu okuyucunun anlayamayacağı kadar teknik olabilir. Lütfen geliştirmeye yardım et -e uzman olmayanlar için anlaşılır hale getirinteknik detayları kaldırmadan. (Eylül 2013) (Bu şablon mesajını nasıl ve ne zaman kaldıracağınızı öğrenin) |
| Sınıf | Sıra hizalaması |
|---|---|
| En kötü durumda verim | |
| En kötü durumda uzay karmaşıklığı |

Needleman-Wunsch algoritması bir algoritma kullanılan biyoinformatik -e hizalamak protein veya nükleotid diziler. İlk uygulamalardan biriydi dinamik program biyolojik dizileri karşılaştırmak için. Algoritma, Saul B. Needleman ve Christian D. Wunsch tarafından geliştirildi ve 1970 yılında yayınlandı.[1] Algoritma, temelde büyük bir problemi (ör. Tam sekans) bir dizi daha küçük probleme böler ve daha büyük probleme en uygun çözümü bulmak için daha küçük problemlerin çözümlerini kullanır.[2] Bazen şu şekilde de anılır: optimum eşleşme algoritma ve küresel uyum tekniği. Needleman-Wunsch algoritması, özellikle küresel hizalamanın kalitesi çok önemli olduğunda, optimum global hizalama için hala yaygın olarak kullanılmaktadır. Algoritma, olası her hizalamaya bir puan atar ve algoritmanın amacı, en yüksek puana sahip tüm olası hizalamaları bulmaktır.
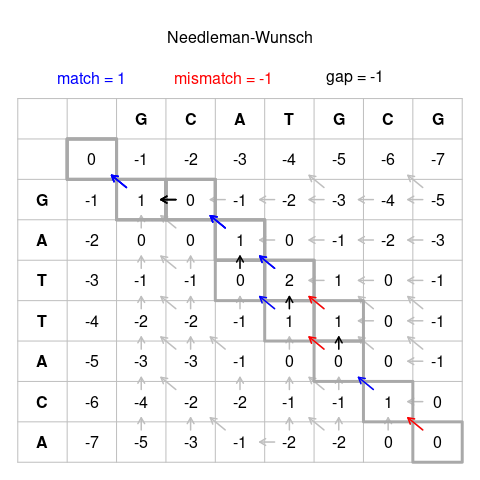
Sonuçlar: Sıralar En iyi hizalamalar --------- ---------------------- GCATGCU GCATG-CU GCA-TGCU GCAT-GCUGATTACA G-ATTACA G -ATTACA G-ATTACABaşlatma adımının yorumlanması: Yukarıdaki şekildeki en soldaki sütun şu şekilde yorumlanabilir (her dizinin önüne bir "tutamaç" koyun, burada + olarak açıklanmıştır): Hizalama: + GCATGCU + GATTACAScore: 0 // Tutamaç eşleşir tutacak, puan kazanmaz skor −3Alignment: + GCATGCU + GATTACAScore: 0 // 4 boşluk, skor −4 ... Aynı şey en üstteki satır için de yapılabilir.
Giriş
Bu algoritma herhangi ikisi için kullanılabilir Teller. Bu kılavuz iki küçük DNA dizileri şemada gösterildiği gibi örnekler olarak:
GCATGCUGATTACA
Izgarayı inşa etmek
İlk önce, yukarıdaki Şekil 1'de gösterildiği gibi bir ızgara oluşturun. İlk dizeyi üçüncü sütunun üstünden başlatın ve diğer dizeyi üçüncü satırın başlangıcından başlatın. Sütun ve satır başlıklarının geri kalanını Şekil 1'deki gibi doldurun. Kılavuzda henüz numara olmamalıdır.
| G | C | Bir | T | G | C | U | ||
|---|---|---|---|---|---|---|---|---|
| G | ||||||||
| Bir | ||||||||
| T | ||||||||
| T | ||||||||
| Bir | ||||||||
| C | ||||||||
| Bir |
Bir puanlama sistemi seçmek
Ardından, her bir harf çiftini nasıl puanlayacağınıza karar verin. Yukarıdaki örneği kullanarak, olası bir hizalama adayı şunlar olabilir:
12345678
GCATG-CU
G-ATTACA
Harfler eşleşebilir, uyumsuz olabilir veya bir boşlukla eşleştirilebilir (silme veya ekleme (indel )):
- Eşleşme: Mevcut dizindeki iki harf aynıdır.
- Uyumsuzluk: Mevcut dizindeki iki harf farklı.
- Indel (INsertion veya DELetion): En iyi hizalama, bir harfin diğer dizedeki bir boşluğa hizalanmasını içerir.
Bu senaryoların her birine bir puan atanır ve tüm eşleşmelerin puanlarının toplamı, tüm hizalama adayının puanıdır. Puanların atanması için farklı sistemler mevcuttur; bazılarının ana hatları Puanlama sistemleri aşağıdaki bölüm. Şimdilik Needleman ve Wunsch tarafından kullanılan sistem[1] kullanılacak:
- Maç: +1
- Uyumsuzluk veya Indel: −1
Yukarıdaki Örnek için, hizalamanın puanı 0 olacaktır:
GCATG-CU
G-ATTACA
+−++−−+− −> 1*4 + (−1)*4 = 0
Tabloyu doldurmak
İkinci satırda, ikinci sütunda sıfırla başlayın. Her hücrenin puanını hesaplayarak hücrelerde satır satır ilerleyin. Skor, hücrenin soluna, üstüne veya soluna (köşegen) komşu hücrelerin skorları karşılaştırılarak ve eşleşme, uyumsuzluk veya indel için uygun skor eklenerek hesaplanır. Üç olasılığın her biri için aday puanlarını hesaplayın:
- Üst veya sol hücreden gelen yol bir indel eşleşmesini temsil eder, bu nedenle sol ve üst hücrenin puanlarını alın ve her birine indel puanını ekleyin.
- Köşegen yol bir eşleşmeyi / uyumsuzluğu temsil eder, bu nedenle sol üst köşegen hücrenin puanını alın ve satır ve sütundaki karşılık gelen tabanlar (harfler) eşleşiyorsa eşleşme için puanı veya uymuyorsa uyumsuzluk puanını ekleyin.
Hücre için ortaya çıkan puan, üç aday puanın en yüksek olanıdır.
İkinci satır için "üst" veya "sol üst" hücre olmadığı için, her bir hücrenin puanını hesaplamak için yalnızca soldaki mevcut hücre kullanılabilir. Bu nedenle, önceki puandan bir indel'i temsil ettiği için sağa her vardiya için 1 eklenir. Bu, ilk satırın 0, −1, −2, −3, −4, −5, −6, −7 olmasına neden olur. Aynısı ilk sütun için de geçerlidir çünkü yalnızca her hücrenin üzerindeki mevcut puan kullanılabilir. Böylece ortaya çıkan tablo şu şekildedir:
| G | C | Bir | T | G | C | U | ||
|---|---|---|---|---|---|---|---|---|
| 0 | −1 | −2 | −3 | −4 | −5 | −6 | −7 | |
| G | −1 | |||||||
| Bir | −2 | |||||||
| T | −3 | |||||||
| T | −4 | |||||||
| Bir | −5 | |||||||
| C | −6 | |||||||
| Bir | −7 |
Her 3 yönde de mevcut puanlara sahip ilk durum, ilk harflerimizin (bu durumda G ve G) kesişmesidir. Çevreleyen hücreler aşağıdadır:
| G | ||
|---|---|---|
| 0 | −1 | |
| G | −1 | X |
Bu hücrede üç olası aday toplamı vardır:
- Sol üstteki çapraz komşunun puanı 0'dır. G ve G'nin eşleşmesi bir eşleşmedir, bu nedenle eşleşme için puanı ekleyin: 0 + 1 = 1
- En üstteki komşunun puanı −1'dir ve oradan hareket etmek bir indel'i temsil eder, bu nedenle indel için puanı ekleyin: (−1) + (−1) = (−2)
- Sol komşunun puanı da -1'dir, bir indel'i temsil eder ve ayrıca (−2) üretir.
En yüksek aday 1'dir ve hücreye girilir:
| G | ||
|---|---|---|
| 0 | −1 | |
| G | −1 | 1 |
En yüksek aday puanı veren hücre de kaydedilmelidir. Yukarıdaki şekil 1'de tamamlanan diyagramda, bu, satır ve sütun 3'teki hücreden satır ve sütundaki hücreye giden bir ok olarak temsil edilir.
Bir sonraki örnekte, hem X hem de Y için çapraz adım bir uyuşmazlığı temsil eder:
| G | C | ||
|---|---|---|---|
| 0 | −1 | −2 | |
| G | −1 | 1 | X |
| Bir | −2 | Y |
X:
- Üst: (−2) + (- 1) = (−3)
- Sol: (+1) + (- 1) = (0)
- Sol Üst: (−1) + (- 1) = (−2)
Y:
- Üst: (1) + (- 1) = (0)
- Sol: (−2) + (- 1) = (−3)
- Sol Üst: (−1) + (- 1) = (−2)
Hem X hem de Y için en yüksek puan sıfırdır:
| G | C | ||
|---|---|---|---|
| 0 | −1 | −2 | |
| G | −1 | 1 | 0 |
| Bir | −2 | 0 |
En yüksek aday puana iki veya tüm komşu hücrelerden ulaşılabilir:
| T | G | |
|---|---|---|
| T | 1 | 1 |
| Bir | 0 | X |
- Üst: (1) + (- 1) = (0)
- Sol Üst: (1) + (- 1) = (0)
- Sol: (0) + (- 1) = (−1)
Bu durumda, en yüksek aday puana ulaşan tüm yönler, Şekil 1'deki bitmiş diyagramda olası başlangıç hücreleri olarak not edilmelidir, örn. 7. satır ve sütundaki hücrede.
Tabloyu bu şekilde doldurmak, puanları veya tüm olası hizalama adaylarını verir, sağ alttaki hücredeki puan, en iyi hizalama için hizalama puanını temsil eder.
Okları başlangıç noktasına kadar izleme
Okların yönünü izleyerek sağ alttaki hücreden sol üstteki hücreye giden yolu işaretleyin. Bu yoldan, sıra şu kurallara göre oluşturulur:
- Köşegen bir ok bir eşleşme veya uyumsuzluğu temsil eder, bu nedenle sütunun harfi ve başlangıç hücresinin satırının harfi hizalanır.
- Yatay veya dikey bir ok, bir indeli temsil eder. Yatay oklar, satırın harfiyle ("yan" sıra) bir boşluğu ("-") hizalar; dikey oklar, sütunun harfiyle ("üst" sıra) bir boşluğu hizalar.
- Aralarından seçim yapabileceğiniz birden fazla ok varsa, bunlar hizalamaların dallanmasını temsil eder. İki veya daha fazla dalın tümü sağ alttan sol üst hücreye giden yollara aitse, bunlar eşit derecede uygun hizalamalardır. Bu durumda, yolları ayrı hizalama adayları olarak not edin.
Bu kuralların ardından, şekil 1'deki olası bir uyum adayı için adımlar şunlardır:
U → CU → GCU → -GCU → T-GCU → AT-GCU → CAT-GCU → GCAT-GCUA → CA → ACA → TACA → TTACA → ATTACA → -ATTACA → G-ATTACA ↓ (şube) → TGCU → ... → TACA → ...
Puanlama sistemleri
Temel puanlama şemaları
En basit puanlama şemaları her eşleşme, uyumsuzluk ve indel için basitçe bir değer verir. Yukarıdaki adım adım kılavuz, match = 1, mismatch = −1, indel = −1 kullanır. Böylece, hizalama puanı ne kadar düşükse, mesafeyi düzenle, bu puanlama sistemi için yüksek bir puan istenir. Başka bir puanlama sistemi şunlar olabilir:
- Maç = 0
- Indel = 1
- Uyumsuzluk = 1
Bu sistem için hizalama puanı, iki dizi arasındaki düzenleme mesafesini temsil edecektir.Farklı durumlar için farklı puanlama sistemleri tasarlanabilir, örneğin, hizalamanız için boşluklar çok kötü olarak değerlendirilirse, boşlukları ağır şekilde cezalandıran bir puanlama sistemi kullanabilirsiniz. :
- Maç = 0
- Uyumsuzluk = 1
- Indel = 10
Benzerlik matrisi
Daha karmaşık puanlama sistemleri, değerleri yalnızca değişiklik türü için değil, aynı zamanda dahil olan harfler için de tanımlar. Örneğin, A ve A arasındaki bir eşleşmeye 1 verilebilir, ancak T ile T arasında bir eşleşme verilebilir. 4 Burada (ilk puanlama sistemi varsayılarak) Ts eşleşmesine As'dan daha fazla önem verilir, yani Ts eşleşmesi uyum için daha önemli olduğu varsayılmaktadır. Harflere dayalı bu ağırlıklandırma, uyumsuzluklar için de geçerlidir.
Olası tüm harf kombinasyonlarını ve bunların sonuç puanlarını temsil etmek için bir benzerlik matrisi kullanılır. En temel sistem için benzerlik matrisi şu şekilde temsil edilir:
| Bir | G | C | T | |
|---|---|---|---|---|
| Bir | 1 | -1 | -1 | -1 |
| G | -1 | 1 | -1 | -1 |
| C | -1 | -1 | 1 | -1 |
| T | -1 | -1 | -1 | 1 |
Her puan, hücrenin eşleştiği harflerden birinden diğerine geçişi temsil eder. Dolayısıyla bu, tüm olası eşleşmeleri ve silmeleri temsil eder (ACGT'nin bir alfabesi için). Tüm eşleşmelerin köşegen boyunca gittiğine dikkat edin, ayrıca tüm tablonun doldurulması gerekmiyor, sadece bu üçgen çünkü puanlar karşılıklı. = (A → C = C → A için Puan). T-T = 4 kuralını yukarıdan uygularsanız, aşağıdaki benzerlik matrisi üretilir:
| Bir | G | C | T | |
|---|---|---|---|---|
| Bir | 1 | −1 | −1 | −1 |
| G | −1 | 1 | −1 | −1 |
| C | −1 | −1 | 1 | −1 |
| T | −1 | −1 | −1 | 4 |
Belirli bir senaryoya uygun farklı eylemlere ağırlık veren farklı puanlama matrisleri istatistiksel olarak oluşturulmuştur. Ağırlıklı puanlama matrislerine sahip olmak, farklı amino asitlerin değişen frekansı nedeniyle protein dizisi hizalamasında özellikle önemlidir. Her biri belirli senaryolar için daha fazla değişiklik içeren iki geniş puanlama matrisi ailesi vardır:
Boşluk cezası
Dizileri hizalarken genellikle boşluklar (ör. Girintiler) vardır, bazen büyük olanlar. Biyolojik olarak, birden çok tek silme işleminin aksine büyük bir silme işlemi olarak büyük bir boşluğun ortaya çıkması daha olasıdır. Bu nedenle, iki küçük indel, bir büyük indikten daha kötü bir puana sahip olmalıdır. Bunu yapmanın basit ve yaygın yolu, yeni bir indel için büyük bir boşluk başlangıç skoru ve indel'i genişleten her harf için daha küçük bir boşluk uzatma skoru kullanmaktır. Örneğin, new-indel -5'e mal olabilir ve ext-indel -1'e mal olabilir. Bu şekilde aşağıdaki gibi bir hizalama:
GAAAAAATG - A-A-T
Birden çok eşit hizalamaya sahip olan, bazıları birden çok küçük hizalamaya sahip olan şimdi şu şekilde hizalanacak
GAAAAAATGAA ---- T
veya birden çok küçük boşluk yerine 4 uzun boşluklu herhangi bir hizalama.
Gelişmiş algoritma sunumu
Hizalanmış karakterler için puanlar, bir benzerlik matrisi. Buraya, S(a, b) karakterlerin benzerliğidir a ve b. Doğrusal kullanır boşluk cezası burada aradı d.
Örneğin, benzerlik matrisi
| Bir | G | C | T | |
|---|---|---|---|---|
| Bir | 10 | −1 | −3 | −4 |
| G | −1 | 7 | −5 | −3 |
| C | −3 | −5 | 9 | 0 |
| T | −4 | −3 | 0 | 8 |
ardından hizalama:
AGACTAGTTACCGA --- GACGT
−5'lik bir boşluk cezası ile, aşağıdaki puana sahip olacaktır:
- S(A, C) + S(G, G) + S(A, A) + (3 × d) + S(G, G) + S(T, A) + S(T, C) + S(A, G) + S(C, T)
- = −3 + 7 + 10 − (3 × 5) + 7 + (−4) + 0 + (−1) + 0 = 1
En yüksek puana sahip hizalamayı bulmak için iki boyutlu dizi (veya matris ) F tahsis edilir. Satırdaki giriş ben ve sütun j burada ile gösterilir. Sıradaki her karakter için bir satır vardır Birve sıradaki her karakter için bir sütun B. Böylece, boyut dizileri hizalıyorsa n ve mkullanılan bellek miktarı . Hirschberg algoritması dizinin yalnızca bir alt kümesini bellekte tutar ve kullanır boşluk, ancak başka türlü Needleman-Wunsch'a benzer (ve hala gerektirir zaman).



Algoritma ilerledikçe, birincinin hizalanması için en uygun puan olarak atanacaktır. içindeki karakterler Bir ve ilk içindeki karakterler B. iyimserlik ilkesi daha sonra aşağıdaki şekilde uygulanır:


- Temel:


- Optimallik ilkesine dayalı özyineleme:

Bu nedenle, F matrisini hesaplamak için algoritmanın sözde kodu şuna benzer:
d ← Boşluk ceza puanıiçin i = 0 -e uzunluk(A) F (i, 0) ← d * iiçin j = 0 -e uzunluk(B) F (0, j) ← d * jiçin i = 1 -e uzunluk(A) için j = 1 -e uzunluk(B) {Maç ← F (i − 1, j − 1) + S (Aben, Bj) Sil ← F (i − 1, j) + d Ekle ← F (i, j − 1) + d F (i, j) ← max(Eşleştir, Ekle, Sil)}Bir kere F matris hesaplanır, giriş olası tüm hizalamalar arasında maksimum puanı verir. Bu puanı gerçekten veren bir hizalamayı hesaplamak için, sağ alttaki hücreden başlar ve hangisinden geldiğini görmek için değeri olası üç kaynakla (yukarıdaki Eşleştir, Ekle ve Sil) karşılaştırırsınız. Eşleşirse, o zaman ve hizalanırsa, Sil ise, o zaman bir boşlukla hizalı ve Ekle ise, o zaman bir boşlukla hizalı. (Genel olarak, birden fazla seçim aynı değere sahip olabilir ve bu da alternatif optimum hizalamalara yol açar.)



HizalamaA ← "" HizalamaB ← "" i ← uzunluk(A) j ← uzunluk(B)süre (i> 0 veya j> 0) { Eğer (i> 0 ve j> 0 ve F (i, j) == F (ben − 1, j − 1) + S (birben, Bj)) {HizalamaA ← Aben + HizalamaA HizalamaB ← Bj + HizalamaB i ← i - 1 j ← j - 1} Başka Eğer (i> 0 ve F (i, j) == F (i − 1, j) + d) {HizalamaA ← Aben + HizalamaA HizalamaB ← "-" + HizalamaB i ← i - 1} Başka {HizalamaA ← "-" + HizalamaA HizalamaB ← Bj + HizalamaB j ← j - 1}}Karmaşıklık
Puanı hesaplamak tablodaki her hücre için bir operasyon. Dolayısıyla, iki uzunluk dizisi için algoritmanın zaman karmaşıklığı ve dır-dir .[3] Çalışma süresinin iyileştirilmesinin mümkün olduğu gösterilmiştir. kullanmak Dört Rus Yöntemi.[3][4] Algoritma bir alan karmaşıklığının tablosu .[3]





Tarihsel notlar ve algoritma geliştirme
Needleman ve Wunsch tarafından açıklanan algoritmanın asıl amacı, iki proteinin amino asit dizilerindeki benzerlikleri bulmaktı.[1]
Needleman ve Wunsch, hizalamanın yalnızca eşleşmeler ve uyumsuzluklarla cezalandırıldığı ve boşlukların cezasının olmadığı durum için algoritmalarını açıkça tanımlar (d= 0). 1970 tarihli orijinal yayın, özyineleme.

Karşılık gelen dinamik programlama algoritması kübik zaman alır. Makale ayrıca, özyinelemenin keyfi boşluk cezalandırma formüllerini barındırabileceğine de dikkat çekiyor:
Yapılan her boşluk için bir sayı çıkarılan bir ceza faktörü, boşluğa izin vermenin önünde bir engel olarak değerlendirilebilir. Ceza faktörü, boşluğun boyutunun ve / veya yönünün bir fonksiyonu olabilir. [sayfa 444]
Aynı problem için ikinci dereceden çalışma süresine sahip daha iyi bir dinamik programlama algoritması (boşluk cezası yok) ilk kez tanıtıldı[5] David Sankoff tarafından 1972. Benzer ikinci dereceden zaman algoritmaları bağımsız olarak T.K.Vintsyuk tarafından keşfedildi.[6] 1968'de konuşma işleme için ("zaman atlama" ) ve Robert A. Wagner ve Michael J. Fischer[7] 1974'te dize eşleştirme için.
Needleman ve Wunsch problemlerini benzerliği en üst düzeye çıkarmak açısından formüle etti. Diğer bir olasılık, mesafeyi düzenle diziler arasında Vladimir Levenshtein. Peter H. Sellers gösterdi[8] 1974'te bu iki sorunun eşdeğer olduğu.
Needleman – Wunsch algoritması, optimum küresel uyum özellikle küresel uyumun kalitesi çok önemli olduğunda. Bununla birlikte, algoritma, iki dizinin uzunluğunun çarpımı ile orantılı olarak zaman ve mekan açısından pahalıdır ve bu nedenle uzun diziler için uygun değildir.
Son gelişmeler, kaliteyi korurken algoritmanın zaman ve alan maliyetini iyileştirmeye odaklanmıştır. Örneğin, 2013'te Hızlı Optimal Global Sıra Hizalama Algoritması (FOGSAA),[9] Needleman-Wunsch algoritması da dahil olmak üzere nükleotid / protein dizilerinin diğer optimal global hizalama yöntemlerinden daha hızlı hizalanmasını önerdi. Makale, Needleman-Wunsch algoritması ile karşılaştırıldığında, FOGSAA'nın oldukça benzer nükleotid dizileri için% 70-90 (>% 80 benzerlik ile) ve% 30-80 benzerliğe sahip diziler için% 54-70 zaman kazanımı sağladığını iddia etmektedir.
Needleman – Wunsch algoritmasını kullanan küresel hizalama araçları
- EMBOSS İğnesi ve EMBOSS Sedye Global Hizalama Araçları
- İki nükleotid dizisi için Needleman-Wunsch hizalaması
- MathWorks - Needleman-Wunsch algoritmasını kullanarak iki diziyi global olarak hizalayın
- BitKeeper - Kaynak Kontrol Yönetim Yazılımı
Biyoinformatik dışındaki uygulamalar
Bilgisayar stereo görüşü
Stereo eşleştirme, bir çift stereo görüntüden 3B yeniden yapılandırma sürecinde önemli bir adımdır. Görüntüler düzeltildiğinde, nükleotid ve protein dizilerinin hizalanması ile eşleştirme arasında bir analoji çizilebilir. piksel ait tarama hatları, çünkü her iki görev de iki karakter dizisi arasında en uygun yazışmayı sağlamayı amaçlamaktadır. Bir stereo çiftinin "sağ" görüntüsü, "sol" görüntünün mutasyona uğramış bir versiyonu olarak görülebilir: gürültü ve bireysel kamera hassasiyeti piksel değerlerini değiştirir (yani karakter ikameleri); ve farklı görüş açısı, önceden kapatılmış verileri ortaya çıkarır ve yeni tıkanmalar (yani karakterlerin eklenmesi ve silinmesi) ortaya çıkarır. Sonuç olarak, Needleman-Wunsch algoritmasındaki küçük değişiklikler, onu stereo eşleştirme için uygun hale getirir.[10] Doğruluk açısından performanslar son teknoloji ürünü olmamasına rağmen, algoritmanın göreceli basitliği, gömülü sistemler.[11]
Birçok uygulamada görüntü düzeltme, örn. tarafından kamera rezeksiyonu veya kalibrasyon, bazen imkansız veya pratik değildir, çünkü doğru düzeltme modellerinin hesaplama maliyeti, bunların kullanılmasını yasaklamaktadır. gerçek zaman uygulamalar. Dahası, bu modellerden hiçbiri, bir kamera merceği beklenmedik bir görüntü sergilediğinde uygun değildir. çarpıtma yağmur damlaları, hava koşullarına dayanıklı örtüler veya tozdan kaynaklananlar gibi. Needleman-Wunsch algoritmasını genişleterek, 'sol' görüntüdeki bir çizgi, üç boyutlu bir dizide (veya matriste) en yüksek puana sahip hizalamayı bularak 'sağ' görüntüdeki bir eğri ile ilişkilendirilebilir. Deneyler, bu tür bir uzantının, düzeltilmemiş veya bozulmuş görüntüler arasında yoğun piksel eşleşmesine izin verdiğini göstermiştir.[12]
Ayrıca bakınız
- Wagner – Fischer algoritması
- Smith – Waterman algoritması
- Sıralı madencilik
- Levenshtein mesafesi
- Dinamik zaman atlama
- Sıra hizalaması
Referanslar
- ^ a b c Needleman, Saul B. & Wunsch, Christian D. (1970). "İki proteinin amino asit dizisindeki benzerliklerin araştırılmasına uygulanabilen genel bir yöntem". Moleküler Biyoloji Dergisi. 48 (3): 443–53. doi:10.1016/0022-2836(70)90057-4. PMID 5420325.
- ^ "biyoinformatik". Alındı 10 Eylül 2014.
- ^ a b c Wing-Kin., Sung (2010). Biyoinformatikte algoritmalar: pratik bir giriş. Boca Raton: Chapman & Hall / CRC Press. sayfa 34–35. ISBN 9781420070330. OCLC 429634761.
- ^ Masek, William; Paterson, Michael (Şubat 1980). "Daha hızlı bir algoritma hesaplama dizisi mesafeleri düzenleme". Bilgisayar ve Sistem Bilimleri Dergisi. 20: 18–31. doi:10.1016/0022-0000(80)90002-1.
- ^ Sankoff D (1972). "Silme / ekleme kısıtlamaları altında eşleşen diziler". ABD Ulusal Bilimler Akademisi Bildirileri. 69 (1): 4–6. Bibcode:1972PNAS ... 69 .... 4S. doi:10.1073 / pnas.69.1.4. PMC 427531. PMID 4500555.
- ^ Vintsyuk TK (1968). "Dinamik programlama ile konuşma ayırt etme". Kibernetika. 4: 81–88. doi:10.1007 / BF01074755. S2CID 123081024.
- ^ Wagner RA, Fischer MJ (1974). "Dizeden dizgeye düzeltme sorunu". ACM Dergisi. 21 (1): 168–173. doi:10.1145/321796.321811. S2CID 13381535.
- ^ Satıcılar PH (1974). "Evrimsel mesafelerin teorisi ve hesaplanması üzerine". SIAM Uygulamalı Matematik Dergisi. 26 (4): 787–793. doi:10.1137/0126070.
- ^ Chakraborty, Angana; Bandyopadhyay, Sanghamitra (29 Nisan 2013). "FOGSAA: Hızlı Optimal Global Sıra Hizalama Algoritması". Bilimsel Raporlar. 3: 1746. Bibcode:2013NatSR ... 3E1746C. doi:10.1038 / srep01746. PMC 3638164. PMID 23624407.
- ^ Dieny R., Thevenon J., Martinez-del-Rincon J., Nebel J.-C. (2011) "Stereo yazışmalar için biyoinformatikten ilham alan algoritma ". Uluslararası Bilgisayarla Görme Teorisi ve Uygulamaları Konferansı, 5–7 Mart, Vilamoura - Algarve, Portekiz.
- ^ Madeo S., Pelliccia R., Salvadori C., Martinez-del-Rincon J., Nebel J.-C. (2014) "Gömülü sistemler için optimize edilmiş bir stereo görüntü uygulaması: RGB ve Kızılötesi görüntülere uygulama". Gerçek Zamanlı Görüntü İşleme Dergisi ".
- ^ Thevenon, J; Martinez-del-Rincon, J; Dieny, R; Nebel, J-C (2012). Dinamik programlama kullanılarak düzeltilmemiş ve bozulmuş görüntüler arasında yoğun piksel eşleşmesi. Uluslararası Bilgisayarlı Görme Teorisi ve Uygulamaları Konferansı. Roma.
Dış bağlantılar
Bu makalenin kullanımı Dış bağlantılar Wikipedia'nın politikalarına veya yönergelerine uymayabilir. (Mayıs 2017) (Bu şablon mesajını nasıl ve ne zaman kaldıracağınızı öğrenin) |
- NW-align: Needleman-Wunsch algoritması (çevrimiçi sunucu ve kaynak kodu) ile bir protein dizisinden diziye hizalama programı
- Grid için Paralel Needleman-Wunsch Algoritması - Tahir Naveed, Imitaz Saeed Siddiqui ve Shaftab Ahmed tarafından uygulama - Bahria Üniversitesi
- Needleman-Wunsch Algoritması Haskell Kodu olarak
- Needleman – Wunsch'un Javascript tabanlı canlı bir demosu
- Needleman-Wunsch Algoritmasının Javascript tabanlı etkileşimli görsel açıklaması
- BABA. - algoritmayı görsel olarak açıklayan bir uygulama (kaynak ile).
- NW ve sekans hizalamaya yönelik uygulamalarının net bir açıklaması
- Teknoloji Blogunda Sıra Hizalama Teknikleri
- Biostrings Diğerlerinin yanı sıra Needleman – Wunsch algoritmasını uygulayan R paketi
- Needleman-Wunsch Algoritması Haxe Kodu olarak