OCRopus - OCRopus
 | |
| Geliştirici (ler) | Thomas Breuel, DFKI |
|---|---|
| İlk sürüm | 9 Nisan 2007[1] |
| Kararlı sürüm | 1.3.3 / 16 Aralık 2017 |
| Depo | |
| Yazılmış | C ++ ve Python |
| İşletim sistemi | FreeBSD, Linux, Mac OS X |
| Tür | Optik karakter tanıma |
| Lisans | Apache Lisansı v2.0 |
| İnternet sitesi | github |
OCRopus bir Bedava belge analizi ve optik karakter tanıma (OCR) sistemi, Apache Lisansı v2.0 çok modüler bir tasarıma sahip komut satırı arayüzleri.
OCRopus, Thomas Breuel öncülüğünde geliştirilmiştir. Alman Yapay Zeka Araştırma Merkezi içinde Kaiserslautern, Almanya ve sponsorluğunda Google.
Açıklama
OCRopus, özellikle yüksek hacimde kullanım için tasarlanmıştır sayısallaştırma gibi kitap projeleri Google Kitapları, İnternet Arşivi veya kütüphaneler. Çok sayıda dil ve yazı tipi desteklenecektir.[2] Ancak masaüstü ve ofis uygulamalarında veya görme engelliler için uygulama olarak da kullanılabilir.
OCRopus'un ana bileşenleri oluşturulmuştur:
Bu bileşenler için tekli veya çoklu komut dosyaları mevcuttur. modüler yaklaşım bireysel iş akışlarının kullanılmasına ve ayrı adımların değiştirilmesine izin verir.
Varsayılan olarak OCRopus, İngilizce metinler için bir model ve Fraktur. Bu modeller yazıya atıfta bulunur ve büyük ölçüde gerçek dilden bağımsızdır.[3] Yeni karakterler veya dil çeşitleri yeni veya ek olarak eğitilebilir.
Son metin tanıma şuna dayanır: tekrarlayan sinir ağları (LSTM ) ve bir dil modeli gerektirmez. Bu, aynı zamanda İngilizce, Almanca ve Fransızca için iyi tanınma sonuçlarının gösterildiği dilden bağımsız modellerin eğitilmesini mümkün kılar.[4] Buna ek olarak Latin alfabesi gibi başka komut dosyaları için sonuçlar var Sanskritçe, Urduca, Devanagari ve Yunan.
Uygun bir eğitimle çok iyi tespit oranları elde edilebilir. Bu ekstra çaba, günümüzde artık yaygın olmayan ve diğer OCR yazılımlarının odağında olmayan zor belgeler veya komut dosyaları için özellikle değerlidir.[5][6]
Tarih
9 Nisan 2007'de OCRopus, gelişmiş OCR teknolojileri geliştirmek için Google sponsorluğundaki bir proje olarak duyuruldu.[1] Finansman üç yıllık bir süre için verildi ve özellikle doktora ve doktora sonrası pozisyonlarda kapandı. DFKI ve Kaiserslautern Üniversitesi. Buna karşılık, OCRopus ayrıca otomatik metin tanıma için kullanıldı. Google Kitap Arama.[7] Açık kaynak lisansı altında lisanslama, endüstriyel ve akademik araştırmalar arasındaki işbirliğini kolaylaştırmak için en başından itibaren yapılmıştır.[8] OCRopus, Andrew W. Mellon Vakfı ve BMBF.[9]
İlk alfa sürümü 0.1, 22 Ekim 2007'de yayınlandı ve bunu Aralık 2007 ile Mayıs 2009 arasında izleyen birkaç ön sürüm, Mart 2010'da kararlı bir sürüm 0.4.4'e ulaştı.[10] Başlangıçta yazılım şu ülkelerde geliştirilmiştir: C ++, Python ve Lua ile Reçel olarak inşa sistemi. Tam kaynak kodun yeniden düzenlenmesi Python modülleri 0.5 sürümünde yapıldı ve yayınlandı (Haziran 2012).[11]
Başlangıçta, Tesseract tek metin tanıma modülü olarak kullanıldı. 2009'dan beri (sürüm 0.4) Tesseract yalnızca bir eklenti olarak destekleniyordu. Bunun yerine, kendi geliştirdiği bir metin tanıyıcı (ayrıca segment tabanlı) kullanıldı.[12] Bu tanıyıcı daha sonra OpenFST ile birlikte kullanıldı[13] için dil modelleme tanıma adımından sonra. 2013'ten itibaren, tekrarlayan sinir ağları (LSTM ), Kasım 2014'te sürüm 1.0'ın piyasaya sürülmesiyle tek tanıyan olan teklif edildi.[14][15]
Kaynak kodu yönetilir GitHub ve bir geliştirici topluluğu tarafından korunur ve geliştirilir.[16] OCRopus'un güncel sürümü 1.3.3'tür (Aralık 2017).[17]
Kullanım
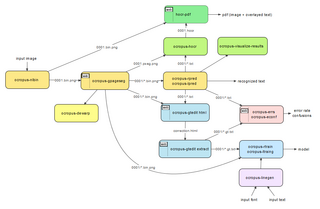
OCRopus komut satırından kullanılabilir. Bir kez kurulduktan sonra, giriş görüntülerini belirleyerek çağrılabilir. Tanınan metni çıktılayacaktır. standart çıktı doğrudan veya şu şekilde yazın hOCR (HTML tabanlı) kodu dosyalara dönüştürür ve buradan aranabilir bir PDF'ye dönüştürülebilir. Daha hassas kontrol gerekirse, belirli işlemleri gerçekleştirmek için (örneğin tek bir satırı tanıma) komut satırında seçenekler belirtilebilir.[18]
Bir resimdeki metni tanımak için OCRopus çağrılarına örnek:
# binarizationocropus-nlbin testleri gerçekleştir / ersch.png -o kitap # sayfa düzeni analizi gerçekleştirocropus-gpageseg book / 0001.bin.png # metin satırı tanıma gerçekleştirme (fraktur modeli ile) ocropus-rpred -m models / fraktur.pyrnn.gz book / 0001 / *. bin.png # generate HTML outputocropus-hocr book / 0001.bin.png -o book / 0001.htmlDiğer araçlar, OCRopus'un eğitim kısmına odaklanır. Latin, Yunanca, Kiril ve Hint alfabelerinden metin çıkarmak için OCRopus modelleri vardır.[19]
Referanslar
- ^ a b Breuel, Thomas (9 Nisan 2007). "OCRopus Açık Kaynak OCR Sistemini Duyurusu". Google Developers Blogu. Alındı 29 Aralık 2017.
- ^ Breuel, Thomas (2009). OCRopus OCR Sisteminde Son İlerleme. Uluslararası Çok Dilli OCR Çalıştayı Bildirileri. MOCR '09. New York, NY, ABD: ACM. s. 2: 1–2: 10. doi:10.1145/1577802.1577805. ISBN 9781605586984.
- ^ "Modeller". ocropy wiki. Alındı 5 Ocak 2018.
- ^ Ul-Hasan, Adnan; Breuel, Thomas M. (2013). LSTM Ağlarını Kullanarak Dilden Bağımsız OCR Oluşturabilir miyiz?. 4. Uluslararası Çok Dilli OCR Çalıştayı Bildirileri. MOCR '13. New York, NY, ABD: ACM. s. 9: 1–9: 5. doi:10.1145/2505377.2505394. ISBN 9781450321143.
- ^ Springmann, Uwe (1 Aralık 2016). "OCR für alte Drucke". Informatik-Spektrum (Almanca'da). 39 (6): 459–462. doi:10.1007 / s00287-016-1004-3. ISSN 0170-6012.
- ^ Simistira, F .; Ul-Hassan, A .; Papavassiliou, V .; Gatos, B .; Katsouros, V .; Liwicki, M. (Ağustos 2015). LSTM ağlarını kullanarak tarihsel Yunan poliktonik yazılarının tanınması. 2015 13. Uluslararası Belge Analizi ve Tanıma Konferansı (ICDAR). s. 766–770. doi:10.1109 / icdar.2015.7333865. ISBN 978-1-4799-1805-8.
- ^ "OCRopus araştırma projesi". www.dfki.de. Alındı 5 Ocak 2018.
- ^ Breuel, Thomas M. (28 Ocak 2008). "OCRopus açık kaynak OCR sistemi". Bildiriler Cilt 6815, Belge Tanıma ve Erişim XV. Belge Tanıma ve Erişim XV. 6815: 68150F – 68150F – 15. Bibcode:2008SPIE.6815E..0FB. CiteSeerX 10.1.1.99.8505. doi:10.1117/12.783598.
- ^ "ocropus proje web sitesi". Google Proje Barındırma. Ocak 2019. Arşivlenen orijinal 24 Aralık 2012.
- ^ "Eski sürümler - ocropy". GitHub. Alındı 5 Ocak 2018.
- ^ "OCRopus 0.5". Google Toplulukları. 2 Haziran 2012.
- ^ OCRopus, Tesseract ile varsayılan olarak bağlantı kurmaz.
- ^ Resmi OpenFST web sitesi.
- ^ "ocropy - sürüm v1.0". GitHub. 2 Kasım 2014. Alındı 5 Ocak 2018.
- ^ Breuel, T. M .; Ul-Hasan, A .; Al-Azawi, M. A .; Shafait, F. (Ağustos 2013). LSTM Ağlarını Kullanan Basılı İngilizce ve Fraktur için Yüksek Performanslı OCR. 2013 12. Uluslararası Belge Analizi ve Tanıma Konferansı. s. 683–687. doi:10.1109 / icdar.2013.140. ISBN 978-0-7695-4999-6.
- ^ "ocropy: Belge analizi ve OCR için Python tabanlı araçlar", GitHub, alındı 5 Ocak 2018
- ^ "Okropiyi serbest bırakır". GitHub. Alındı 5 Ocak 2018.
- ^ "ocropy wiki". GitHub. Alındı 30 Aralık 2017.
- ^ "okropi modelleri". GitHub. Alındı 13 Mart 2018.
Dış bağlantılar
- okropi açık GitHub
- GitHub'da Ocropy wiki
- IUPR Yayın Sunucusu (OCRopus'ta kullanılan birçok algoritmanın arkasındaki makaleler)