Turing testi - Turing test
| Bir serinin parçası |
| Yapay zeka |
|---|
Sözlük |
Turing testi, başlangıçta taklit oyun tarafından Alan Turing 1950'de[2] bir makinenin yeteneğinin testidir. akıllı davranış sergilemek bir insanınkine eşdeğer veya ondan ayırt edilemez. Turing, bir insan değerlendiricinin, bir insan ile insan benzeri yanıtlar üretmek için tasarlanmış bir makine arasındaki doğal dil konuşmalarını yargılayacağını öne sürdü. Değerlendirici, konuşmadaki iki taraftan birinin bir makine olduğunun ve tüm katılımcıların birbirinden ayrılacağının farkında olacaktır. Konuşma, bilgisayar klavyesi ve ekranı gibi yalnızca metin içeren bir kanalla sınırlandırılacak ve böylece sonuç makinenin kelimeleri konuşma olarak dönüştürme yeteneğine bağlı olmayacaktır.[3] Değerlendirici, makineyi insandan güvenilir bir şekilde ayırt edemezse, makinenin testi geçtiği söylenir. Test sonuçları, makinenin doğru verebilme yeteneğine bağlı değildir. soruların cevapları, sadece cevaplarının bir insanın vereceği cevaplara ne kadar benzediğini.
Test, Turing tarafından 1950 tarihli makalesinde tanıtıldı "Bilgi İşlem Makineleri ve İstihbarat "şurada çalışırken Manchester Üniversitesi.[4] Şöyle başlıyor: "Makineler düşünebilir mi?" Sorusunu düşünmeyi öneriyorum.'"Düşünme" nin tanımlanması zor olduğu için, Turing "soruyu onunla yakından ilgili olan ve nispeten belirsiz kelimelerle ifade edilen bir başkasıyla değiştirmeyi" seçer.[5] Turing, sorunun yeni biçimini, iki oyuncunun doğru cinsiyetini belirlemek için sorgu görevlisinin başka bir odadaki bir erkek ve bir kadına sorular sorduğu "taklit oyun" adı verilen üç kişilik bir oyun olarak tanımlıyor. Turing'in yeni sorusu şudur: "Dünyada iyi iş çıkarabilecek düşünülebilir dijital bilgisayarlar var mı? taklit oyun?"[2] Turing, bu sorunun gerçekten cevaplanabilecek bir soru olduğuna inanıyordu. Makalenin geri kalanında, "makineler düşünebilir" önermesine yapılan tüm büyük itirazlara karşı çıktı.[6]
Turing, testini ilk kez tanıttığından beri, hem oldukça etkili hem de geniş çapta eleştirildiğini kanıtladı ve testte önemli bir kavram haline geldi. yapay zeka felsefesi.[7][8][9]. John Searle'inki gibi bu eleştirilerden bazıları Çin odası, kendileri tartışmalıdır.
Tarih
Felsefi arka plan
Makinelerin düşünmesinin mümkün olup olmadığı sorusu uzun bir geçmişe sahiptir ve bu, arasındaki ayrımda sağlam bir şekilde yerleşiktir. düalist ve materyalist aklın görüşleri. René Descartes 1637'de Turing testinin özelliklerini önceden şekillendirdi Yöntem Üzerine Söylem yazdığı zaman:
[H] çünkü insan endüstrisi tarafından birçok farklı otomata veya hareketli makine yapılabilir ... Çünkü, bir makinenin oluştuğunu kolayca anlayabiliriz, böylece kelimeler söyler ve hatta cisimsel türden eylemlere bazı tepkiler verebiliriz. organlarında bir değişiklik meydana getiren; örneğin, belirli bir bölüme dokunulduğunda, ona ne söylemek istediğimizi sorabilir; başka bir kısımda canının yandığını iddia edebilir ve bu böyle devam eder. Ancak, onun varlığında söylenebilecek her şeye, en düşük insan türünün bile yapabileceği şekilde uygun şekilde cevap verebilmek için konuşmasını çeşitli şekillerde düzenlemesi asla gerçekleşmez.[10]
Descartes burada şunu not eder: Otomata İnsan etkileşimlerine cevap verme yeteneğine sahipler, ancak bu tür otomatların varlığında söylenen şeylere herhangi bir insanın yapabileceği şekilde uygun şekilde cevap veremeyeceğini savunuyor. Bu nedenle Descartes, insanı otomattan ayıran şey olarak uygun dilbilimsel tepkinin yetersizliğini tanımlayarak Turing testini önceden yapılandırır. Descartes, gelecekteki otomatların bu tür bir yetersizliğin üstesinden gelme olasılığını göz önünde bulundurmakta başarısızdır ve bu nedenle, kavramsal çerçevesini ve kriterini önceden belirtse bile Turing testini bu şekilde önermemektedir.
Denis Diderot onun içinde formüle eder Pensées felsefeleri Turing testi kriteri:
"Her şeye cevap verebilecek bir papağan bulurlarsa, tereddüt etmeden zeki bir varlık olduğunu iddia ederim."[11]
Bu, onunla aynı fikirde olduğu anlamına gelmez, ancak o zamanlar materyalistlerin zaten ortak bir argümanı olduğu anlamına gelir.
Düalizme göre, zihin dır-dir fiziksel olmayan (veya en azından fiziksel olmayan özellikler )[12] ve bu nedenle tamamen fiziksel terimlerle açıklanamaz. Materyalizme göre zihin fiziksel olarak açıklanabilir, bu da yapay olarak üretilen zihinlerin olasılığını açık bırakır.[13]
1936'da filozof Alfred Ayer standart felsefi sorusu olarak kabul edildi diğer zihinler: Başkalarının da bizim yaşadığımız bilinçli deneyimlere sahip olduğunu nasıl bileceğiz? Kitabında Dil, Gerçek ve Mantık Ayer, bilinçli bir adam ile bilinçsiz bir makineyi birbirinden ayırmak için bir protokol önerdi: "Bilinçli görünen bir nesnenin gerçekten bilinçli bir varlık olmadığını, yalnızca bir kukla veya bir makine olduğunu iddia etmek için sahip olabileceğim tek zemin, bilincin varlığının veya yokluğunun belirlendiği deneysel testlerden birini karşılayamaz. "[14] (Bu öneri Turing testine çok benzer, ancak zekadan çok bilinçle ilgilidir. Üstelik Ayer'in popüler felsefi klasiğinin Turing'e aşina olduğu kesin değildir.) Diğer bir deyişle, bir şey başarısız olursa bilinçli değildir. bilinç testi.
Alan Turing
Birleşik Krallık'taki araştırmacılar, yapay zeka alanının kurulmasından on yıl öncesine kadar "makine zekası" nı araştırıyorlardı (AI ) 1956'da araştırma.[15] Bu, üyeleri arasında ortak bir konuydu. Oran Kulübü gayri resmi bir İngiliz grubu sibernetik ve elektronik Alan Turing'i içeren araştırmacılar.[16]
Özellikle Turing, makine zekası kavramını en az 1941'den beri ele alıyordu.[17] ve "bilgisayar zekası" nın bilinen en eski sözlerinden biri 1947'de kendisi tarafından yapılmıştır.[18] Turing'in "Intelligent Machinery" adlı raporunda,[19] "makinelerin akıllı davranış göstermesinin mümkün olup olmadığı sorusunu" araştırdı.[20] ve bu soruşturmanın bir parçası olarak, sonraki testlerinin öncüsü olarak kabul edilebilecek şeyi önerdi:
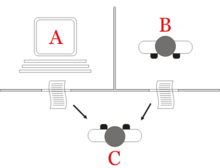
Çok fena olmayan bir satranç oyunu oynayacak bir kağıt makinesi tasarlamak zor değil.[21] Şimdi deney için denek olarak üç adam alın. A, B ve C. A ve C oldukça zayıf satranç oyuncuları olacak, B kağıt makinesini çalıştıran operatör. ... Hareketleri iletmek için bazı düzenlemelerle iki oda kullanılır ve C ile A veya kağıt makinesi arasında bir oyun oynanır. C hangisini oynadığını söylemek oldukça zor olabilir.[22]
"Bilgi İşlem Makineleri ve İstihbarat " (1950 ) Turing tarafından yalnızca makine zekasına odaklanan ilk yayınlanan makaledir. Turing 1950 tarihli makalesine "Makineler düşünebilir mi?" Sorusunu düşünmeyi öneriyorum.'"[5] Onun vurguladığı gibi, böyle bir soruya geleneksel yaklaşım, tanımlar, hem "makine" hem de "zeka" terimlerini tanımlıyor. Turing bunu yapmamayı seçti; bunun yerine soruyu yenisiyle değiştirir, "onunla yakından ilgilidir ve nispeten net kelimelerle ifade edilir."[5] Özünde, "Makineler düşünebilir mi?" Sorusunu değiştirmeyi öneriyor. "Makineler (düşünen varlıklar olarak) yapabileceğimizi yapabilir mi?"[23] Turing'e göre yeni sorunun avantajı, "bir erkeğin fiziksel ve entelektüel kapasiteleri arasında oldukça keskin bir çizgi" çizmesidir.[24]
Bu yaklaşımı göstermek için Turing, bir Parti oyunu Bir erkeğin ve bir kadının ayrı odalara girdiği ve misafirlerin bir dizi soru yazarak ve geri gönderilen daktilo ile yazılmış cevapları okuyarak onları birbirinden ayırmaya çalıştığı "taklit oyunu" olarak bilinen,. Bu oyunda hem erkek hem de kadın misafirleri birbirlerinin öteki olduğuna ikna etmeyi amaçlıyor. (Huma Shah, oyunun bu iki kişilik versiyonunun Turing tarafından sadece okuyucuya makine-insan soru-cevap testini tanıtmak için sunulduğunu savunuyor.[25]Turing, oyunun yeni versiyonunu şöyle anlattı:
Şimdi şu soruyu soruyoruz: "Bir makine bu oyunda A'nın rolünü alırsa ne olur?" Soru soran kişi, oyun bir erkek ve bir kadın arasında oynandığında olduğu gibi, oyun böyle oynandığında da yanlış karar verecek mi? Bu sorular bizim orijinalimiz olan "Makineler düşünebilir mi?"[24]
Yazının ilerleyen kısımlarında Turing, bir yargıcın yalnızca bir bilgisayar ve bir adamla konuşmasını içeren "eşdeğer" bir alternatif formülasyon önermektedir.[26] Bu formülasyonların hiçbiri, bugün daha genel olarak bilinen Turing testinin versiyonuyla tam olarak eşleşmezken, 1952'de bir üçüncü önerdi. Bu versiyonda, Turing'in bir BBC radyo yayıncılığında, bir jüri bir bilgisayara sorular sorar ve bilgisayarın rolü, jürinin önemli bir bölümünü gerçekten bir erkek olduğuna inandırmaktır.[27]
Turing'in makalesi, aleyhindeki tüm önemli argümanları içeren dokuz varsayılan itirazı değerlendirdi. yapay zeka makalenin yayınlanmasından bu yana geçen yıllarda ortaya çıkan belgeler (bkz. "Bilgi İşlem Makineleri ve İstihbarat ").[6]
ELIZA ve PARRY
1966'da, Joseph Weizenbaum Turing testini geçen bir program yarattı. Program olarak bilinen ELIZA, bir kullanıcının anahtar kelimeler için yazdığı yorumları inceleyerek çalıştı. Bir anahtar kelime bulunursa, kullanıcının yorumlarını dönüştüren bir kural uygulanır ve ortaya çıkan cümle döndürülür. Bir anahtar kelime bulunamazsa, ELIZA ya genel bir yanıtla ya da önceki yorumlardan birini tekrarlayarak yanıt verir.[28] Buna ek olarak Weizenbaum, ELIZA'yı bir Rogerian psikoterapist, ELIZA'nın "gerçek dünyadan neredeyse hiçbir şey bilmiyormuş gibi davranma özgürlüğüne" izin veriyor.[29] Bu tekniklerle, Weizenbaum'un programı bazı insanları gerçek bir kişiyle konuştuklarına inandırmayı başardı, bazı konular "ELIZA'nın [...] değil insan."[29] Bu nedenle, bazıları tarafından ELIZA'nın Turing testini geçebilen programlardan biri (belki de ilk) olduğu iddia edilmektedir.[29][30] bu görüş oldukça tartışmalı olsa da (bkz. altında ).
Kenneth Colby yaratıldı SAVUŞTURMA 1972'de "Tutumlu ELIZA" olarak tanımlanan bir program.[31] Bir davranışını modellemeye çalıştı paranoyak şizofren Weizenbaum tarafından kullanılana benzer (daha gelişmişse) bir yaklaşım kullanarak. Çalışmayı doğrulamak için, PARRY 1970'lerin başında Turing testinin bir varyasyonu kullanılarak test edildi. Bir grup deneyimli psikiyatrist, PARRY'yi çalıştıran bilgisayarların ve gerçek hastaların bir kombinasyonunu analiz etti. teleprinters. 33 psikiyatristten oluşan başka bir gruba görüşmelerin dökümleri gösterildi. Daha sonra iki gruptan "hastaların" hangilerinin insan, hangilerinin bilgisayar programı olduğunu belirlemeleri istendi.[32] Psikiyatristler zamanın yalnızca yüzde 48'inde doğru tanımlamayı yapabildiler - bu rastgele tahminle tutarlı bir rakam.[33]
21. yüzyılda, bu programların sürümleri (artık "sohbet robotları ") insanları kandırmaya devam edin." CyberLover ", bir kötü amaçlı yazılım programı, İnternet kullanıcılarını "kimlikleriyle ilgili bilgileri ifşa etmeye veya bilgisayarlarına kötü amaçlı içerik gönderecek bir web sitesini ziyaret etmeye yönlendirmeye" ikna ederek avlıyor.[34] Program, "kişisel verilerini toplamak için çevrimiçi ilişkiler arayan" insanlarla flört eden bir "Sevgililer günü riski" olarak ortaya çıktı.[35]
Çin odası
John Searle 1980 gazetesi Akıllar, Beyinler ve Programlar önerdi "Çin odası "deneyi düşündü ve Turing testinin bir makinenin düşünüp düşünemeyeceğini belirlemek için kullanılamayacağını savundu. Searle, yazılımın (ELIZA gibi), anlamadıkları sembolleri manipüle ederek Turing testini geçebileceğini belirtti. İnsanlarla aynı anlamda "düşünme" olarak tanımlanamaz. Bu nedenle, Searle, Turing testinin bir makinenin düşünebildiğini kanıtlayamayacağı sonucuna varıyor.[36] Turing testinin kendisi gibi, Searle'ın argümanı da geniş çapta eleştirildi[37] ve çok onaylandı.[38]
Searle ve diğerleri gibi argümanlar akıl felsefesi Zekanın doğası, akıllı makinelerin olasılığı ve 1980'ler ve 1990'lar boyunca devam eden Turing testinin değeri hakkında daha yoğun bir tartışma başlattı.[39]
Loebner Ödülü
Loebner Ödülü, Kasım 1991'de düzenlenen ilk yarışma ile pratik Turing testleri için yıllık bir platform sağlar.[40] Tarafından sigortalanmıştır Hugh Loebner. Cambridge Davranış Araştırmaları Merkezi Massachusetts Amerika Birleşik Devletleri, 2003 yarışmasına kadar olan ödülleri düzenledi. Loebner'ın açıkladığı gibi, rekabetin yaratılmasının bir nedeni, en azından kısmen, yapay zeka araştırmasının durumunu ilerletmektir, çünkü hiç kimse 40 yıldır tartışmasına rağmen Turing testini uygulamak için adımlar atmamıştı.[41]
1991'deki ilk Loebner Ödülü yarışması, her iki popüler basında Turing testinin uygulanabilirliği ve onu takip etmenin değeri hakkında yenilenen bir tartışmaya yol açtı.[42] ve akademi.[43] İlk yarışma, saf sorgulayıcıları yanlış kimlik belirlemeleri için kandırmayı başaran, tanımlanabilir bir zeka içermeyen akılsız bir program tarafından kazanıldı. Bu, Turing testinin bazı eksikliklerinin altını çizdi (tartışıldı altında ): Kazanan, en azından kısmen, "insan yazım hatalarını taklit edebildiği" için kazandı;[42] bilgisiz sorgulayıcılar kolayca kandırıldı;[43] ve AI'daki bazı araştırmacılar, testin yalnızca daha verimli araştırmalardan kaynaklanan bir dikkat dağıtıcı olduğunu hissetmeye yönlendirildi.[44]
Gümüş (yalnızca metin) ve altın (sesli ve görsel) ödüller hiç kazanılmadı. Ancak yarışma, jüri üyelerinin görüşlerine göre o yılki katılımlar arasında "en insani" konuşma davranışını sergileyen bilgisayar sistemi için her yıl bronz madalya ile ödüllendirildi. Yapay Dilbilimsel İnternet Bilgisayar Varlığı (A.L.I.C.E.) son zamanlarda üç kez bronz ödül kazandı (2000, 2001, 2004). AI öğrenmek Jabberwacky 2005 ve 2006'da kazandı.
Loebner Ödülü, konuşma zekasını test eder; kazananlar tipik olarak gevezelik programlar veya Yapay Konuşma Varlıkları (ACE). Erken Loebner Ödülü kuralları konuşmaları kısıtladı: Her giriş ve gizli insan tek bir konu hakkında konuştu,[45] bu nedenle sorgulayıcılar, varlık etkileşimi başına bir sorgulama satırı ile sınırlandırıldı. Sınırlı konuşma kuralı 1995 Loebner Ödülü için kaldırıldı. Yargıç ve varlık arasındaki etkileşim süresi Loebner Ödüllerinde değişiklik gösterdi. Loebner 2003'te Surrey Üniversitesi'nde, her sorgulayıcıya bir varlık, makine veya gizli insanla etkileşime girmesi için beş dakika izin verildi. 2004 ile 2007 arasında, Loebner Ödüllerinde izin verilen etkileşim süresi yirmi dakikadan fazlaydı.
Versiyonlar

Saul Traiger, Turing testinin en az üç ana versiyonu olduğunu savunuyor, bunlardan ikisi "Hesaplama Makineleri ve Zeka" olarak sunuluyor ve biri "Standart Yorum" olarak tanımlıyor.[46] "Standart Yorum" un Turing tarafından mı yoksa onun makalesinin yanlış okunmasına dayanarak mı anlatıldığı konusunda bazı tartışmalar olsa da, bu üç versiyon eşdeğer olarak kabul edilmemektedir.[46] ve güçlü ve zayıf yönleri farklıdır.[47]
Huma Shah, Turing'in kendisinin bir makinenin düşünüp düşünemeyeceğiyle ilgilendiğini ve bunu incelemek için basit bir yöntem sağladığını belirtiyor: insan-makine soru-cevap oturumları aracılığıyla.[48] Shah, Turing'in tanımladığı bir taklit oyununun iki farklı şekilde pratikleştirilebileceğini savunuyor: a) bire bir sorgulayıcı-makine testi ve b) bir makinenin bir insanla eşzamanlı karşılaştırması, her ikisi de paralel olarak bir sorgulayıcı tarafından sorgulanır.[25] Turing testi, performans kapasitesindeki bir ayırt edilemezlik testi olduğundan, sözlü versiyon, sözlü ve sözsüz (robotik) olmak üzere tüm insan performans kapasitesine doğal olarak genelleme yapar.[49]
Taklit oyun
Turing'in orijinal makalesi, üç oyuncunun yer aldığı basit bir parti oyununu anlatıyor. Oyuncu A bir erkek, oyuncu B bir kadın ve oyuncu C (sorgulayıcı rolünü oynayan) her iki cinsten. Taklit oyunda, C oyuncusu ne A oyuncusunu ne de B oyuncusunu göremez ve onlarla yalnızca yazılı notlar yoluyla iletişim kurabilir. Oyuncu A ve oyuncu B'ye sorular sorarak, oyuncu C, hangisinin erkek hangisinin kadın olduğunu belirlemeye çalışır. Oyuncu A'nın rolü sorgulayıcıyı yanlış karar vermesi için kandırmaktır, oysa B oyuncusu sorgulayıcıya doğru kararı vermesi için yardım etmeye çalışır.[7]
Turing sonra sorar:
Bir makine bu oyunda A'nın rolünü aldığında ne olacak? Sorgu görevlisi, oyun bir erkek ve bir kadın arasında oynandığında olduğu gibi, oyun böyle oynandığında da yanlış karar verecek mi? Bu sorular bizim orijinalimiz olan "Makineler düşünebilir mi?"[24]

İkinci versiyon daha sonra Turing'in 1950 tarihli makalesinde yayınlandı. Orijinal taklit oyun testine benzer şekilde, A oyuncusunun rolü bir bilgisayar tarafından gerçekleştirilir. Ancak, B oyuncusunun rolünü kadın yerine erkek oynar.
Dikkatimizi belirli bir dijital bilgisayara verelim C. Bu bilgisayarı yeterli bir depolama alanına sahip olacak şekilde değiştirerek, hareket hızını uygun şekilde artırarak ve ona uygun bir program sağlayarak, C Taklit oyunda, B'nin bir erkek tarafından alınmasıyla, A'nın rolünü tatmin edici bir şekilde oynaması sağlanabilir mi?[24]
Bu versiyonda, hem A oyuncusu (bilgisayar) hem de B oyuncusu, sorgulayıcıyı yanlış bir karar vermesi için kandırmaya çalışıyor.
Standart yorumlama
Yaygın anlayışa göre, Turing testinin amacı, bir bilgisayarın sorgulayıcıyı insan olduğuna inanması için kandırıp kandırmayacağını belirlemek değil, daha çok bir bilgisayarın yapıp yapamayacağını taklit etmek bir insan.[7] Bu yorumun Turing tarafından kasıtlı olup olmadığı konusunda bazı tartışmalar olsa da Sterrett,[50] ve bu nedenle, ikinci sürümü bununla birleştirirken, Traiger gibi diğerleri[46] - bu yine de "standart yorum" olarak görülebilecek bir şeye yol açmıştır. Bu versiyonda, oyuncu A bir bilgisayardır ve B oyuncusu her iki cinsiyetten bir kişidir. Sorgulayıcının rolü, hangisinin erkek hangisinin kadın olduğunu belirlemek değil, hangisinin bilgisayar hangisinin insan olduğunu belirlemektir.[51] Standart yorumlamadaki temel sorun, sorgulayan kişinin hangi yanıtlayanın insan hangisinin makine olduğunu ayırt edememesidir. Süre ile ilgili sorunlar vardır, ancak standart yorum genellikle bu sınırlamayı makul olması gereken bir şey olarak kabul eder.
Taklit oyun ve standart Turing testi
Turing testinin alternatif formülasyonlarından hangisinin amaçladığı konusunda tartışma çıktı.[50] Sterrett, 1950 tarihli makalesinden iki farklı testin çıkarılabileceğini savunuyor ve hız Turing'in sözlerine denk değiller. Parti oyununu kullanan ve başarı frekanslarını karşılaştıran test, "Orijinal Taklit Oyun Testi" olarak adlandırılırken, bir insan ve bir makine ile konuşan bir insan yargıçtan oluşan test, "Standart Turing Testi" olarak adlandırılır. Sterrett'in bunu taklit oyunun ikinci versiyonu yerine "standart yorum" ile eşitlediğine dikkat çekiyor. Sterrett, standart Turing testinin (STT) eleştirmenlerinin öne sürdüğü sorunlara sahip olduğunu kabul eder, ancak bunun aksine, bu şekilde tanımlanan orijinal taklit oyun testinin (OIG testi) çok önemli bir fark nedeniyle birçoğuna bağışık olduğunu hisseder: STT, makine zekası için bir kriter belirlemede insan performansını kullansa da, insan performansına benzerliği kriter haline getirmez. Bir insan OIG testinde başarısız olabilir, ancak başarısızlığın beceriklilik eksikliğini gösterdiği bir zeka testinin erdemidir: OIG testi, sadece "insan konuşma davranışının simülasyonunu" değil, zeka ile ilişkili becerikliliği gerektirir. OIG testinin genel yapısı, taklit oyunların sözlü olmayan versiyonlarıyla bile kullanılabilir.[52]
Hala diğer yazarlar[53] Turing'i, taklit oyunun parti versiyonunu kullanarak önerdiği testin, bu taklitte karşılaştırmalı başarı sıklığı kriterine dayandığına dair Turing'in ifadesinin nasıl dikkate alınacağını belirtmeden, taklit oyunun kendisinin bir test olduğunu öne sürdüğü şeklinde yorumlamıştır. oyunun bir turunda başarılı olma kapasitesinden ziyade oyun.
Saygın, belki de orijinal oyunun, bilgisayarın katılımını gizlediği için daha az taraflı bir deneysel tasarım önermenin bir yolu olduğunu öne sürdü.[54] Taklit oyun aynı zamanda standart yorumlamada bulunmayan bir "sosyal hack" içerir, çünkü oyunda hem bilgisayar hem de erkek insan, olmadıkları biri gibi davranmak zorundadır.[55]
Sorgulayıcı bilgisayar hakkında bilgi sahibi olmalı mı?
Herhangi bir laboratuvar testinin çok önemli bir parçası, bir kontrolün olması gerektiğidir. Turing, testlerinde sorgulayan kişinin katılımcılardan birinin bilgisayar olduğunun farkında olup olmadığını asla netleştirmez. Bununla birlikte, bir Turing testini geçme potansiyeline sahip bir makine olsaydı, çift kör kontrolün gerekli olacağını varsaymak güvenli olurdu.
Orijinal taklit oyuna geri dönmek için, yalnızca A oyuncusunun bir makine ile değiştirileceğini, C oyuncusunun bu değişiklikten haberdar edilmeyeceğini belirtir.[24] Colby, FD Hilf, S Weber ve AD Kramer, PARRY'yi test ettiklerinde, sorgulayanların sorgu sırasında görüşülenlerden bir veya daha fazlasının bilgisayar olduğunu bilmelerine gerek olmadığını varsayarak bunu yaptılar.[56] Ayşe Saygın, Peter Swirski olarak,[57] ve diğerleri, bunun testin uygulanması ve sonucunda büyük bir fark yarattığını vurguladı.[7] Şuna bakan deneysel bir çalışma Gricean maksim ihlalleri Ayşe Saygın, Loebner'in 1994–1999 arasındaki yapay zeka yarışmaları için bire bir (sorgulayıcı-gizli muhatap) Ödülünün transkriptlerini kullanarak, dahil olan bilgisayarları bilen ve bilmeyen katılımcıların yanıtları arasında önemli farklılıklar buldu.[58]
Güçlü
İzlenebilirlik ve basitlik
Turing testinin gücü ve çekiciliği basitliğinden kaynaklanmaktadır. akıl felsefesi, Psikoloji ve modern sinirbilim makinelere uygulanmak için yeterince kesin ve genel olan "zeka" ve "düşünme" tanımlarını sağlayamamışlardır. Bu tür tanımlar olmadan, ana soru yapay zeka felsefesi cevaplanamaz. Turing testi, mükemmel olmasa bile, en azından gerçekte ölçülebilen bir şey sağlar. Bu nedenle, zor bir felsefi soruyu yanıtlamaya yönelik pragmatik bir girişimdir.
Konunun genişliği
Testin formatı sorgulayan kişinin makineye çok çeşitli entelektüel görevler vermesine izin verir. Turing, "soru cevap yönteminin, dahil etmek istediğimiz insan çabasının neredeyse her alanını tanıtmak için uygun göründüğünü" yazdı.[59] John Haugeland "kelimeleri anlamak yeterli değildir; anlamanız gerekir konu aynı zamanda. "[60]
İyi tasarlanmış bir Turing testini geçmek için makinenin kullanması gerekir Doğal lisan, sebep, Sahip olmak bilgi ve öğrenmek. Test, video girişinin yanı sıra nesnelerin geçilebileceği bir "tarama" da içerecek şekilde genişletilebilir: bu, makineyi iyi tasarlanmış bir ürünün yetenekli kullanımını göstermeye zorlar. vizyon ve robotik yanı sıra. Bunlar birlikte, yapay zeka araştırmasının çözmek isteyeceği neredeyse tüm önemli sorunları temsil ediyor.[61]
Feigenbaum testi Turing testi için mevcut olan geniş konu yelpazesinden yararlanmak üzere tasarlanmıştır. Makineyi edebiyat veya edebiyat gibi belirli alanlardaki uzmanların yetenekleriyle karşılaştıran Turing'in soru-cevap oyununun sınırlı bir şeklidir. kimya. IBM 's Watson makine, insan bilgisine karşı makine televizyon yarışması şovunda başarı elde etti, Jeopardy![62][bu paragrafla ilgili mi? ]
Duygusal ve estetik zekaya vurgu
Bir Cambridge matematik mezunu olarak, Turing'in son derece teknik bir alanda uzman bilgisi gerektiren bir bilgisayar zekası testi önermesi ve dolayısıyla beklenti içinde olması beklenebilirdi. konuya daha yeni bir yaklaşım. Bunun yerine, daha önce belirtildiği gibi, çığır açan 1950 makalesinde anlattığı test, bilgisayarın ortak bir parti oyununda başarılı bir şekilde rekabet edebilmesini gerektirir ve bu, tipik bir adam kadar iyi performans göstererek bir dizi soruyu yanıtlayarak Kadın yarışmacı gibi ikna edici bir şekilde davranın.
İnsan cinsel dimorfizminin durumu göz önüne alındığında en eski konulardan biri Bu nedenle, yukarıdaki senaryoda, cevaplanacak soruların ne özelleşmiş gerçeklere dayalı bilgiyi ne de bilgi işleme tekniğini içereceği örtüktür. Bilgisayar için zorluk, daha ziyade, dişinin rolü için empati göstermek ve aynı zamanda karakteristik bir estetik duyarlılığı göstermek olacaktır - her ikisi de Turing'in hayal ettiği bu diyalog parçacığında sergilenmektedir:
- Sorgulayıcı: X lütfen bana saçının uzunluğunu söyler mi?
- Yarışmacı: Saçım döküldü ve en uzun teller yaklaşık dokuz inç uzunluğunda.
Turing hayali diyaloglarından birine bazı özel bilgiler kattığında konu matematik veya elektronik değil, şiirdir:
- Sorgulayıcı: "Seni bir yaz günüyle karşılaştırayım mı" yazan sonenin ilk satırında "bir bahar günü" daha iyi veya daha iyi olmaz mı?
- Tanık: Olmaz taramak.
- Sorgulayıcı: "Bir kış gününe" ne dersiniz? Bu iyi tarayacaktır.
- Tanık: Evet, ama kimse bir kış gününe benzetilmek istemez.
Turing, yapay zekanın bileşenleri olarak empati ve estetik duyarlılığa olan ilgisini bir kez daha ortaya koyuyor; ve yapay zekadan kaynaklanan tehdide karşı artan farkındalığın ışığında,[63] önerildi[64] bu odaklanma belki de Turing açısından kritik bir sezgiyi temsil ediyor, yani duygusal ve estetik zeka bir "dost AI Bununla birlikte, Turing'in bu yönde verebileceği ilham ne olursa olsun, orijinal vizyonunun korunmasına, yani Turing testinin "standart yorumunun" ilan edilmesine bağlı olduğu da belirtilmelidir. - yani, yalnızca söylemsel bir zekaya odaklanan biri - biraz dikkatle görülmelidir.
Zayıf yönler
Turing, Turing testinin bir zeka ölçüsü veya başka herhangi bir insan kalitesi olarak kullanılabileceğini açıkça belirtmedi. "Düşünmek" kelimesine açık ve anlaşılır bir alternatif sunmak istiyordu ve bunu daha sonra "düşünme makineleri" olasılığına yönelik eleştirilere yanıt vermek ve araştırmanın ilerleyebileceği yollar önermek için kullanabilecekti.
Yine de Turing testi, bir makinenin "düşünme yeteneği" veya "zekası" nın bir ölçüsü olarak önerilmiştir. Bu öneri hem filozoflardan hem de bilgisayar bilimcilerinden eleştiri aldı. Sorgulayanın, bir makinenin davranışını insan davranışıyla karşılaştırarak "düşünüyor" olup olmadığını belirleyebileceğini varsayar. Bu varsayımın her unsuru sorgulandı: sorgulayan kişinin yargısının güvenilirliği, yalnızca davranışı karşılaştırmanın değeri ve makineyi bir insanla karşılaştırmanın değeri. Bu ve diğer hususlar nedeniyle, bazı AI araştırmacıları testin kendi alanlarıyla olan ilişkisini sorguladılar.
Genel olarak insan zekası ve zeka

Turing testi, bilgisayarın akıllıca davranıp davranmadığını doğrudan test etmez. Yalnızca bilgisayarın bir insan gibi davranıp davranmadığını test eder. İnsan davranışı ve zeki davranış tam olarak aynı şey olmadığından, test zekayı iki şekilde doğru bir şekilde ölçmede başarısız olabilir:
- Bazı insan davranışları akılsızdır
- Turing testi, makinenin çalışabilmesini gerektirir. herşey zeki olup olmadıklarına bakılmaksızın insan davranışları. Hatta hakarete yatkınlık gibi zeki sayılamayacak davranışları bile test eder,[65] cazibesi Yalan veya basitçe yüksek frekans yazım hataları. Bir makine bu akılsız davranışları ayrıntılı olarak taklit edemezse, testi geçemez.
- Bu itiraz, Ekonomist, başlıklı bir makaledeyapay aptallık "1992'deki ilk Loebner Ödülü yarışmasından kısa bir süre sonra yayınlandı. Makalede, ilk Loebner kazananının zaferinin, en azından kısmen," insan yazım hatalarını taklit etme "yeteneğine bağlı olduğu belirtildi.[42] Turing, oyunun daha iyi "oyuncuları" olabilmeleri için programların çıktılarına hatalar eklemesini önermişti.[66]
- Bazı akıllı davranışlar insanlık dışıdır
- Turing testi, zor problemleri çözme veya orijinal içgörüler elde etme yeteneği gibi son derece zeki davranışları test etmez. Aslında, özellikle makine tarafında aldatma gerektirir: eğer makine Daha bir insandan daha zeki olmak, çok zeki görünmekten kasıtlı olarak kaçınmalıdır. Bir insanın çözmesi neredeyse imkansız olan bir hesaplama problemini çözecek olsaydı, sorgulayıcı programın insan olmadığını bilirdi ve makine testi geçemezdi.
- İnsanların kabiliyetinin ötesindeki zekayı ölçemediği için test, insanlardan daha zeki sistemleri inşa etmek veya değerlendirmek için kullanılamaz. Bu nedenle, süper akıllı sistemleri değerlendirebilecek birkaç test alternatifi önerildi.[67]
Bilinç ve bilinç simülasyonu
Turing testi, konunun nasıl hareketler - makinenin dış davranışı. Bu bağlamda, bir davranışçı veya işlevselci zihin çalışmasına yaklaşım. Örneği ELIZA testi geçen bir makinenin, basit (ama büyük) bir mekanik kurallar listesini izleyerek, hiç düşünmeden ya da aklı olmadan insan konuşma davranışını simüle edebileceğini öne sürüyor.
John Searle bir makinenin "gerçekten" düşünüyor mu yoksa sadece "düşünmeyi simüle eden" mi olduğunu belirlemek için harici davranışın kullanılamayacağını savundu.[36] Onun Çin odası Tartışma, Turing testinin iyi bir operasyonel zeka tanımı olsa bile, makinenin bir zihin, bilinç veya kasıtlılık. (Kasıtlılık, düşüncelerin gücünün bir şey "hakkında" olması için felsefi bir terimdir.)
Turing, orijinal makalesinde bu eleştiri çizgisini öngörmüştü.[68] yazı:
Bilinçle ilgili bir gizem olmadığını düşündüğüm izlenimini vermek istemiyorum. Örneğin, herhangi bir yerelleştirme girişimiyle bağlantılı bir paradoks var. Ancak, bu makalede ilgilendiğimiz soruyu yanıtlamadan önce bu gizemlerin mutlaka çözülmesi gerektiğini düşünmüyorum.[69]
Sorgulayıcıların saflığı ve antropomorfik yanılgı
Pratikte, testin sonuçlarına bilgisayarın zekası tarafından değil, sorgulayan kişinin tavırları, becerisi veya saflığı kolayca hakim olabilir.
Turing, sorgulayan kişinin testi tanımlamasında ihtiyaç duyduğu kesin bilgi ve becerileri belirtmiyor, ancak "ortalama sorgulayıcı" terimini kullanmıştı: "Ortalama sorgulayıcı, doğru yapmak için yüzde 70'ten fazla şansa sahip olmayacaktı. beş dakikalık sorgulamadan sonra kimlik ".[70]
ELIZA gibi chatterbot programları, defalarca şüphelenmeyen insanları insanlarla iletişim kurduklarına inanmaları için kandırdı. Bu durumlarda, "sorgulayıcılar" bilgisayarlarla etkileşim kurma olasılığının farkında bile değildir. Başarılı bir şekilde insan olarak görünmek için, makinenin herhangi bir zekaya sahip olmasına gerek yoktur ve yalnızca insan davranışına yüzeysel bir benzerlik gerekir.
Early Loebner Prize competitions used "unsophisticated" interrogators who were easily fooled by the machines.[43] Since 2004, the Loebner Prize organisers have deployed philosophers, computer scientists, and journalists among the interrogators. Nonetheless, some of these experts have been deceived by the machines.[71]
Human misidentification
One interesting feature of the Turing test is the frequency of the confederate effect, when the confederate (tested) humans are misidentified by the interrogators as machines. It has been suggested that what interrogators expect as human responses is not necessarily typical of humans. As a result, some individuals can be categorised as machines. This can therefore work in favour of a competing machine. The humans are instructed to "act themselves", but sometimes their answers are more like what the interrogator expects a machine to say.[72] This raises the question of how to ensure that the humans are motivated to "act human".
Sessizlik
A critical aspect of the Turing test is that a machine must give itself away as being a machine by its utterances. An interrogator must then make the "right identification" by correctly identifying the machine as being just that. If however a machine remains silent during a conversation, then it is not possible for an interrogator to accurately identify the machine other than by means of a calculated guess.[73]Even taking into account a parallel/hidden human as part of the test may not help the situation as humans can often be misidentified as being a machine.[74]
Impracticality and irrelevance: the Turing test and AI research
Mainstream AI researchers argue that trying to pass the Turing test is merely a distraction from more fruitful research.[44] Indeed, the Turing test is not an active focus of much academic or commercial effort—as Stuart Russell ve Peter Norvig write: "AI researchers have devoted little attention to passing the Turing test."[75] There are several reasons.
First, there are easier ways to test their programs. Most current research in AI-related fields is aimed at modest and specific goals, such as automated scheduling, nesne tanıma, or logistics. To test the intelligence of the programs that solve these problems, AI researchers simply give them the task directly. Russell and Norvig suggest an analogy with the history of flight: Planes are tested by how well they fly, not by comparing them to birds. "Havacılık Mühendisliği texts," they write, "do not define the goal of their field as 'making machines that fly so exactly like güvercinler that they can fool other pigeons.'"[75]
Second, creating lifelike simulations of human beings is a difficult problem on its own that does not need to be solved to achieve the basic goals of AI research. Believable human characters may be interesting in a work of art, a oyun, or a sophisticated Kullanıcı arayüzü, but they are not part of the science of creating intelligent machines, that is, machines that solve problems using intelligence.
Turing wanted to provide a clear and understandable example to aid in the discussion of the yapay zeka felsefesi.[76] John McCarthy observes that the philosophy of AI is "unlikely to have any more effect on the practice of AI research than philosophy of science generally has on the practice of science."[77]
Bilişsel bilim
Robert Fransız (1990) makes the case that an interrogator can distinguish human and non-human interlocutors by posing questions that reveal the low-level (i.e., unconscious) processes of human cognition, as studied by bilişsel bilim. Such questions reveal the precise details of the human embodiment of thought and can unmask a computer unless it experiences the world as humans do.[78]
Varyasyonlar
Numerous other versions of the Turing test, including those expounded above, have been raised through the years.
Reverse Turing test and CAPTCHA
A modification of the Turing test wherein the objective of one or more of the roles have been reversed between machines and humans is termed a reverse Turing test. An example is implied in the work of psychoanalyst Wilfred Bion,[79] who was particularly fascinated by the "storm" that resulted from the encounter of one mind by another. 2000 kitabında,[57] among several other original points with regard to the Turing test, literary scholar Peter Swirski discussed in detail the idea of what he termed the Swirski test—essentially the reverse Turing test. He pointed out that it overcomes most if not all standard objections levelled at the standard version.
Carrying this idea forward, R. D. Hinshelwood[80] described the mind as a "mind recognizing apparatus". The challenge would be for the computer to be able to determine if it were interacting with a human or another computer. This is an extension of the original question that Turing attempted to answer but would, perhaps, offer a high enough standard to define a machine that could "think" in a way that we typically define as characteristically human.
CAPTCHA is a form of reverse Turing test. Before being allowed to perform some action on a website, the user is presented with alphanumerical characters in a distorted graphic image and asked to type them out. This is intended to prevent automated systems from being used to abuse the site. The rationale is that software sufficiently sophisticated to read and reproduce the distorted image accurately does not exist (or is not available to the average user), so any system able to do so is likely to be a human.
Software that could reverse CAPTCHA with some accuracy by analysing patterns in the generating engine started being developed soon after the creation of CAPTCHA.[81]2013 yılında, Vicarious announced that they had developed a system to solve CAPTCHA challenges from Google, Yahoo!, ve PayPal up to 90% of the time.[82]In 2014, Google engineers demonstrated a system that could defeat CAPTCHA challenges with 99.8% accuracy.[83]2015 yılında Shuman Ghosemajumder, former click fraud czar of Google, stated that there were siber suçlu sites that would defeat CAPTCHA challenges for a fee, to enable various forms of fraud.[84]
Konu uzmanı Turing testi
Another variation is described as the konu uzmanı Turing test, where a machine's response cannot be distinguished from an expert in a given field. This is also known as a "Feigenbaum test" and was proposed by Edward Feigenbaum in a 2003 paper.[85]
Total Turing test
The "Total Turing test"[49] variation of the Turing test, proposed by cognitive scientist Stevan Harnad,[86] adds two further requirements to the traditional Turing test. The interrogator can also test the perceptual abilities of the subject (requiring Bilgisayar görüşü ) and the subject's ability to manipulate objects (requiring robotik ).[87]
Elektronik sağlık kayıtları
Yayınlanan bir mektup ACM'nin iletişimi[88] describes the concept of generating a synthetic patient population and proposes a variation of Turing test to assess the difference between synthetic and real patients. The letter states: "In the EHR context, though a human physician can readily distinguish between synthetically generated and real live human patients, could a machine be given the intelligence to make such a determination on its own?" and further the letter states: "Before synthetic patient identities become a public health problem, the legitimate EHR market might benefit from applying Turing Test-like techniques to ensure greater data reliability and diagnostic value. Any new techniques must thus consider patients' heterogeneity and are likely to have greater complexity than the Allen eighth-grade-science-test is able to grade."
Minimum intelligent signal test
The minimum intelligent signal test was proposed by Chris McKinstry as "the maximum abstraction of the Turing test",[89] in which only binary responses (true/false or yes/no) are permitted, to focus only on the capacity for thought. It eliminates text chat problems like anthropomorphism bias, and does not require emulation of unintelligent human behaviour, allowing for systems that exceed human intelligence. The questions must each stand on their own, however, making it more like an IQ testi than an interrogation. It is typically used to gather statistical data against which the performance of artificial intelligence programs may be measured.[90]
Hutter Ödülü
Organizatörleri Hutter Ödülü believe that compressing natural language text is a hard AI problem, equivalent to passing the Turing test.
The data compression test has some advantages over most versions and variations of a Turing test, including:
- It gives a single number that can be directly used to compare which of two machines is "more intelligent."
- It does not require the computer to lie to the judge
The main disadvantages of using data compression as a test are:
- It is not possible to test humans this way.
- It is unknown what particular "score" on this test—if any—is equivalent to passing a human-level Turing test.
Other tests based on compression or Kolmogorov complexity
A related approach to Hutter's prize which appeared much earlier in the late 1990s is the inclusion of compression problems in an extended Turing test.[91] or by tests which are completely derived from Kolmogorov karmaşıklığı.[92]Other related tests in this line are presented by Hernandez-Orallo and Dowe.[93]
Algorithmic IQ, or AIQ for short, is an attempt to convert the theoretical Universal Intelligence Measure from Legg and Hutter (based on Solomonoff's inductive inference ) into a working practical test of machine intelligence.[94]
Two major advantages of some of these tests are their applicability to nonhuman intelligences and their absence of a requirement for human testers.
Ebert testi
The Turing test inspired the Ebert testi proposed in 2011 by film critic Roger Ebert which is a test whether a computer-based sentezlenmiş ses has sufficient skill in terms of intonations, inflections, timing and so forth, to make people laugh.[95]
Tahminler
Turing predicted that machines would eventually be able to pass the test; in fact, he estimated that by the year 2000, machines with around 100 MB of storage would be able to fool 30% of human judges in a five-minute test, and that people would no longer consider the phrase "thinking machine" contradictory.[5] (In practice, from 2009–2012, the Loebner Ödülü chatterbot contestants only managed to fool a judge once,[96] and that was only due to the human contestant pretending to be a sohbet robotu.[97]) He further predicted that makine öğrenme would be an important part of building powerful machines, a claim considered plausible by contemporary researchers in artificial intelligence.[70]
In a 2008 paper submitted to 19th Midwest Artificial Intelligence and Cognitive Science Conference, Dr. Shane T. Mueller predicted a modified Turing test called a "Cognitive Decathlon" could be accomplished within five years.[98]
By extrapolating an üstel büyüme of technology over several decades, fütürist Ray Kurzweil predicted that Turing test-capable computers would be manufactured in the near future. In 1990, he set the year around 2020.[99] By 2005, he had revised his estimate to 2029.[100]
Uzun Bahis Projesi Bet Nr. 1 is a wager of $ 20,000 between Mitch Kapor (pessimist) and Ray Kurzweil (optimist) about whether a computer will pass a lengthy Turing test by the year 2029. During the Long Now Turing Test, each of three Turing test judges will conduct online interviews of each of the four Turing test candidates (i.e., the computer and the three Turing test human foils) for two hours each for a total of eight hours of interviews. The bet specifies the conditions in some detail.[101]
Konferanslar
Turing Colloquium
1990 marked the fortieth anniversary of the first publication of Turing's "Computing Machinery and Intelligence" paper, and, saw renewed interest in the test. Two significant events occurred in that year: The first was the Turing Colloquium, which was held at the Sussex Üniversitesi in April, and brought together academics and researchers from a wide variety of disciplines to discuss the Turing test in terms of its past, present, and future; the second was the formation of the annual Loebner Ödülü rekabet.
Blay Whitby lists four major turning points in the history of the Turing test – the publication of "Computing Machinery and Intelligence" in 1950, the announcement of Joseph Weizenbaum 's ELIZA 1966'da Kenneth Colby yaratılışı SAVUŞTURMA, which was first described in 1972, and the Turing Colloquium in 1990.[102]
2005 Colloquium on Conversational Systems
Kasım 2005'te Surrey Üniversitesi hosted an inaugural one-day meeting of artificial conversational entity developers,[103]attended by winners of practical Turing tests in the Loebner Prize: Robby Garner, Richard Wallace ve Rollo Marangoz. Invited speakers included David Hamill, Hugh Loebner (sponsor of the Loebner Ödülü ) ve Huma Shah.
2008 AISB Symposium
In parallel to the 2008 Loebner Ödülü tutuldu Reading Üniversitesi,[104] Yapay Zeka Çalışmaları ve Davranış Simülasyonu Derneği (AISB), hosted a one-day symposium to discuss the Turing test, organised by John Barnden, Mark Bishop, Huma Shah ve Kevin Warwick.[105]The speakers included the Royal Institution's Director Baroness Susan Greenfield, Selmer Bringsjord, Turing's biographer Andrew Hodges, and consciousness scientist Owen Holland. No agreement emerged for a canonical Turing test, though Bringsjord expressed that a sizeable prize would result in the Turing test being passed sooner.
The Alan Turing Year, and Turing100 in 2012
Throughout 2012, a number of major events took place to celebrate Turing's life and scientific impact. Turing100 group supported these events and also, organised a special Turing test event in Bletchley Parkı on 23 June 2012 to celebrate the 100th anniversary of Turing's birth.
Ayrıca bakınız
- Doğal dil işleme
- Artificial intelligence in fiction
- Blindsight
- Nedensellik
- Bilgisayar oyun botu Turing Testi
- Detroit: İnsan Olun (Game developed by Quantic Dream)
- Açıklama
- Açıklayıcı boşluk
- İşlevselcilik
- Grafik Turing Testi
- HAL 9000 (computer from 2001: Bir Uzay Macerası)
- Ex Machina (film)
- Zor bilinç sorunu
- Ideological Turing Test
- Alan Turing adını alan şeylerin listesi
- Mark V. Shaney (Usenet bot)
- Zihin-vücut sorunu
- Ayna nöron
- Felsefi zombi
- Diğer zihinlerin sorunu
- Tersine mühendislik
- Bilinç
- Simulated reality
- Teknolojik tekillik
- Akıl teorisi
- Esrarengiz vadi
- Voight-Kampff machine (fictitious Turing test from Bıçak Sırtı)
- Westworld (TV dizisi)
- Winograd Şema Mücadelesi
- SHRDLU
Notlar
- ^ Image adapted from Saygin 2000
- ^ a b (Turing 1950, s. 442) Turing does not call his idea "Turing test", but rather the "imitation game"; however, later literature has reserved the term "imitation game" to describe a particular version of the test. Görmek #Versions of the Turing test, altında. Turing gives a more precise version of the question later in the paper: "[T]hese questions [are] equivalent to this, 'Let us fix our attention on one particular digital computer C. Is it true that by modifying this computer to have an adequate storage, suitably increasing its speed of action, and providing it with an appropriate programme, C can be made to play satisfactorily the part of A in the imitation game, the part of B being taken by a man?'" (Turing 1950, s. 442)
- ^ Turing başlangıçta bir teleprinter, 1950'de mevcut olan birkaç salt metin iletişim sisteminden biri. (Turing 1950, s. 433)
- ^ "The Turing Test, 1950". turing.org.uk. The Alan Turing Internet Scrapbook.
- ^ a b c d Turing 1950, s. 433.
- ^ a b Turing 1950, pp. 442–454 ve bakın Russell ve Norvig (2003, s. 948), where they comment, "Turing examined a wide variety of possible objections to the possibility of intelligent machines, including virtually all of those that have been raised in the half century since his paper appeared."
- ^ a b c d e f Saygin 2000.
- ^ Russell ve Norvig 2003, pp. 2–3, 948.
- ^ Swiechowski, Maciej (2020), "Game AI Competitions: Motivation for the Imitation Game-Playing Competition" (PDF), Proceedings of the 15th Conference on Computer Science and Information Systems (FedCSIS 2020), IEEE Publishing: 155–160, alındı 8 Eylül 2020.
- ^ Descartes, René (1996). Yöntem Üzerine Söylem ve İlk Felsefe Üzerine Meditasyonlar. New Haven & London: Yale University Press. pp.34 –35. ISBN 978-0300067729.
- ^ Diderot, D. (2007), Pensees Philosophiques, Addition aux Pensees Philosophiques, [Flammarion], p. 68, ISBN 978-2-0807-1249-3
- ^ For an example of property dualism, see Qualia.
- ^ Noting that materialism does not necessitate the possibility of artificial minds (for example, Roger Penrose ), any more than dualism necessarily precludes the possibility. (Örneğin bkz. Mülkiyet ikiliği.)
- ^ Ayer, A. J. (2001), "Language, Truth and Logic", Doğa, Penguen, 138 (3498): 140, Bibcode:1936Natur.138..823G, doi:10.1038/138823a0, ISBN 978-0-334-04122-1, S2CID 4121089
- ^ Dartmouth conferences of 1956 are widely considered the "birth of AI". (Crevier 1993, s. 49)
- ^ McCorduck 2004, s. 95.
- ^ Copeland 2003, s. 1.
- ^ Copeland 2003, s. 2.
- ^ "Intelligent Machinery" (1948) was not published by Turing, and did not see publication until 1968 in:
- Evans, A. D. J.; Robertson (1968), Cybernetics: Key Papers, University Park Press
- ^ Turing 1948, s. 412.
- ^ In 1948, working with his former undergraduate colleague, DG Champernowne, Turing began writing a chess program for a computer that did not yet exist and, in 1952, lacking a computer powerful enough to execute the program, played a game in which he simulated it, taking about half an hour over each move. The game was recorded, and the program lost to Turing's colleague Alick Glennie, although it is said that it won a game against Champernowne's wife.
- ^ Turing 1948, s.[sayfa gerekli ].
- ^ Harnad 2004, s. 1.
- ^ a b c d e Turing 1950, s. 434.
- ^ a b Shah 2010.
- ^ Turing 1950, s. 446.
- ^ Turing 1952, s. 524–525. Turing does not seem to distinguish between "man" as a gender and "man" as a human. In the former case, this formulation would be closer to the imitation game, whereas in the latter it would be closer to current depictions of the test.
- ^ Weizenbaum 1966, s. 37.
- ^ a b c Weizenbaum 1966, s. 42.
- ^ Thomas 1995, s. 112.
- ^ Bowden 2006, s. 370.
- ^ Colby et al. 1972, s. 42.
- ^ Saygin 2000, s. 501.
- ^ Withers, Steven (11 December 2007), "Flirty Bot Passes for Human", iTWire
- ^ Williams, Ian (10 December 2007), "Online Love Seerkers Warned Flirt Bots", V3
- ^ a b Searle 1980.
- ^ There are a large number of arguments against Searle's Chinese room. Birkaçı:
- Hauser, Larry (1997), "Searle's Chinese Box: Debunking the Chinese Room Argument", Akıllar ve Makineler, 7 (2): 199–226, doi:10.1023/A:1008255830248, S2CID 32153206.
- Rehman, Warren. (19 July 2009), Argument against the Chinese Room Argument, dan arşivlendi orijinal 19 Temmuz 2010'da.
- Thornley, David H. (1997), Why the Chinese Room Doesn't Work, dan arşivlendi orijinal on 26 April 2009
- ^ M. Bishop & J. Preston (eds.) (2001) Essays on Searle's Chinese Room Argument. Oxford University Press.
- ^ Saygin 2000, s. 479.
- ^ Sundman 2003.
- ^ Loebner 1994.
- ^ a b c "Artificial Stupidity" 1992.
- ^ a b c Shapiro 1992, s. 10–11 and Shieber 1994, diğerleri arasında.
- ^ a b Shieber 1994, s. 77.
- ^ "Turing test, on season 4, episode 3". Scientific American Frontiers. Chedd-Angier Prodüksiyon Şirketi. 1993–1994. PBS. Arşivlendi 2006'daki orjinalinden.
- ^ a b c Traiger 2000.
- ^ Saygin 2008.
- ^ Şah 2011.
- ^ a b Oppy, Graham & Dowe, David (2011) Turing Testi. Stanford Felsefe Ansiklopedisi.
- ^ a b Moor 2003.
- ^ Traiger 2000, s. 99.
- ^ Sterrett 2000.
- ^ Genova 1994, Hayes & Ford 1995, Heil 1998, Dreyfus 1979
- ^ R.Epstein, G. Roberts, G. Poland, (eds.) Parsing the Turing Test: Philosophical and Methodological Issues in the Quest for the Thinking Computer. Springer: Dordrecht, Netherlands
- ^ Thompson, Clive (July 2005). "The Other Turing Test". Issue 13.07. KABLOLU dergi. Alındı 10 Eylül 2011.
As a gay man who spent nearly his whole life in the closet, Turing must have been keenly aware of the social difficulty of constantly faking your real identity. And there's a delicious irony in the fact that decades of AI scientists have chosen to ignore Turing's gender-twisting test – only to have it seized upon by three college-age women
. (Tam versiyon ). - ^ Colby et al. 1972.
- ^ a b Swirski 2000.
- ^ Saygin & Cicekli 2002.
- ^ Turing 1950, under "Critique of the New Problem".
- ^ Haugeland 1985, s. 8.
- ^ "These six disciplines," write Stuart J. Russell ve Peter Norvig, "represent most of AI." Russell ve Norvig 2003, s. 3
- ^ Watson:
- "Watson Wins 'Jeopardy!' The IBM Challenge", Sony Resimleri, 16 February 2011, archived from orijinal 22 Mayıs 2011 tarihinde
- Shah, Huma (5 April 2011), Turing's misunderstood imitation game and IBM's Watson success
- ^ Urban, Tim (February 2015). "The AI Revolution: Our Immortality or Extinction". Bekle Ama Neden. Alındı 5 Nisan 2015.
- ^ Smith, G. W. (27 March 2015). "Art and Artificial Intelligence". ArtEnt. Arşivlendi 25 Haziran 2017 tarihinde orjinalinden. Alındı 27 Mart 2015.
- ^ Saygin & Cicekli 2002, pp. 227–258.
- ^ Turing 1950, s. 448.
- ^ Several alternatives to the Turing test, designed to evaluate machines more intelligent than humans:
- Jose Hernandez-Orallo (2000), "Beyond the Turing Test", Mantık, Dil ve Bilgi Dergisi, 9 (4): 447–466, CiteSeerX 10.1.1.44.8943, doi:10.1023/A:1008367325700, S2CID 14481982.
- D L Dowe & A R Hajek (1997), "A computational extension to the Turing Test", Proceedings of the 4th Conference of the Australasian Cognitive Science Society, dan arşivlendi orijinal 28 Haziran 2011'de, alındı 21 Temmuz 2009.
- Shane Legg & Marcus Hutter (2007), "Universal Intelligence: A Definition of Machine Intelligence" (PDF), Akıllar ve Makineler, 17 (4): 391–444, arXiv:0712.3329, Bibcode:2007arXiv0712.3329L, doi:10.1007/s11023-007-9079-x, S2CID 847021, dan arşivlendi orijinal (PDF) 18 Haziran 2009, alındı 21 Temmuz 2009.
- Hernandez-Orallo, J; Dowe, D L (2010), "Measuring Universal Intelligence: Towards an Anytime Intelligence Test", Yapay zeka, 174 (18): 1508–1539, doi:10.1016/j.artint.2010.09.006.
- ^ Russell ve Norvig (2003, pp. 958–960) identify Searle's argument with the one Turing answers.
- ^ Turing 1950.
- ^ a b Turing 1950, s. 442.
- ^ Shah & Warwick 2010.
- ^ Kevin Warwick; Huma Shah (June 2014). "Human Misidentification in Turing Tests". Deneysel ve Teorik Yapay Zeka Dergisi. 27 (2): 123–135. doi:10.1080/0952813X.2014.921734. S2CID 45773196.
- ^ Warwick, Kevin; Shah, Huma (4 March 2017). "Taking the fifth amendment in Turing's imitation game" (PDF). Deneysel ve Teorik Yapay Zeka Dergisi. 29 (2): 287–297. doi:10.1080/0952813X.2015.1132273. ISSN 0952-813X. S2CID 205634569.
- ^ Warwick, Kevin; Shah, Huma (4 March 2015). "Human misidentification in Turing tests". Deneysel ve Teorik Yapay Zeka Dergisi. 27 (2): 123–135. doi:10.1080/0952813X.2014.921734. ISSN 0952-813X. S2CID 45773196.
- ^ a b Russell ve Norvig 2003, s. 3.
- ^ Turing 1950, under the heading "The Imitation Game," where he writes, "Instead of attempting such a definition I shall replace the question by another, which is closely related to it and is expressed in relatively unambiguous words."
- ^ McCarthy, John (1996), "The Philosophy of Artificial Intelligence", What has AI in Common with Philosophy?
- ^ French, Robert M., "Subcognition and the Limits of the Turing Test", Zihin, 99 (393): 53–65
- ^ Bion 1979.
- ^ Hinshelwood 2001.
- ^ Malik, Jitendra; Mori, Greg, Breaking a Visual CAPTCHA
- ^ Pachal, Pete, Captcha FAIL: Researchers Crack the Web's Most Popular Turing Test
- ^ Tung, Liam, Google algorithm busts CAPTCHA with 99.8 percent accuracy
- ^ Ghosemajumder, Shuman, The Imitation Game: The New Frontline of Security
- ^ McCorduck 2004, s. 503–505, Feigenbaum 2003. The subject matter expert test is also mentioned in Kurzweil (2005)
- ^ Gent, Edd (2014), The Turing Test: brain-inspired computing's multiple-path approach
- ^ Russell & Norvig 2010, s. 3.
- ^ Cacm Staff (2017). "A leap from artificial to intelligence". ACM'nin iletişimi. 61: 10–11. doi:10.1145/3168260.
- ^ http://tech.groups.yahoo.com/group/arcondev/message/337
- ^ McKinstry, Chris (1997), "Minimum Intelligent Signal Test: An Alternative Turing Test", Canadian Artificial Intelligence (41)
- ^ D L Dowe & A R Hajek (1997), "A computational extension to the Turing Test", Proceedings of the 4th Conference of the Australasian Cognitive Science Society, dan arşivlendi orijinal 28 Haziran 2011'de, alındı 21 Temmuz 2009.
- ^ Jose Hernandez-Orallo (2000), "Beyond the Turing Test", Mantık, Dil ve Bilgi Dergisi, 9 (4): 447–466, CiteSeerX 10.1.1.44.8943, doi:10.1023/A:1008367325700, S2CID 14481982.
- ^ Hernandez-Orallo & Dowe 2010.
- ^ An Approximation of the Universal Intelligence Measure, Shane Legg and Joel Veness, 2011 Solomonoff Memorial Conference
- ^ Alex_Pasternack (18 April 2011). "Bir MacBook Roger Ebert'e Sesini Verebilir, Ama Bir iPod Hayatını Kurtardı (Video)". Anakart. Arşivlenen orijinal 6 Eylül 2011'de. Alındı 12 Eylül 2011.
Turing'in yapay zeka standardından sonra buna "Ebert Testi" diyor ...
- ^ "Loebner | the Latest Social Media News & Updates".
- ^ "Prizewinning chatbot steers the conversation".
- ^ Shane T. Mueller (2008), "Is the Turing Test Still Relevant? A Plan for Developing the Cognitive Decathlon to Test Intelligent Embodied Behavior" (PDF), Paper Submitted to the 19th Midwest Artificial Intelligence and Cognitive Science Conference: 8pp, archived from orijinal (PDF) 5 Kasım 2010'da, alındı 8 Eylül 2010
- ^ Kurzweil 1990.
- ^ Kurzweil 2005.
- ^ Kapor, Mitchell; Kurzweil, Ray, "By 2029 no computer – or "machine intelligence" – will have passed the Turing Test", The Arena for Accountable Predictions: A Long Bet
- ^ Whitby 1996, s. 53.
- ^ ALICE Anniversary and Colloquium on Conversation, A.L.I.C.E. Artificial Intelligence Foundation, archived from orijinal 16 Nisan 2009, alındı 29 Mart 2009
- ^ Loebner Prize 2008, Reading Üniversitesi, alındı 29 Mart 2009[kalıcı ölü bağlantı ]
- ^ AISB 2008 Symposium on the Turing Test, Society for the Study of Artificial Intelligence and the Simulation of Behaviour, archived from orijinal 18 Mart 2009, alındı 29 Mart 2009
Referanslar
- "Artificial Stupidity", Ekonomist, 324 (7770): 14, 1 August 1992
- Bion, W.S. (1979), "Making the best of a bad job", Clinical Seminars and Four Papers, Abingdon: Fleetwood Press.
- Bowden, Margaret A. (2006), Mind As Machine: A History of Cognitive Science, Oxford University Press, ISBN 978-0-19-924144-6
- Colby, K. M.; Hilf, F. D.; Weber, S .; Kraemer, H. (1972), "Turing-like indistinguishability tests for the validation of a computer simulation of paranoid processes", Yapay zeka, 3: 199–221, doi:10.1016/0004-3702(72)90049-5
- Copeland, Jack (2003), Moor, James (ed.), "The Turing Test", Turing Testi: Yapay Zekanın Zorlu StandardıSpringer, ISBN 978-1-4020-1205-1
- Crevier, Daniel (1993), Yapay Zeka: Yapay Zeka için Kesintisiz Arayış, New York, NY: BasicBooks, ISBN 978-0-465-02997-6
- Dreyfus, Hubert (1979), Bilgisayarlar Hala Yapamam, New York: MIT Press, ISBN 978-0-06-090613-9
- Feigenbaum, Edward A. (2003), "Some challenges and grand challenges for computational intelligence", ACM Dergisi, 50 (1): 32–40, doi:10.1145/602382.602400, S2CID 15379263
- French, Robert M. (1990), "Subcognition and the Limits of the Turing Test", Zihin, 99 (393): 53–65, doi:10.1093/mind/xcix.393.53, S2CID 38063853
- Genova, J. (1994), "Turing's Sexual Guessing Game", Sosyal Epistemoloji, 8 (4): 314–326, doi:10.1080/02691729408578758
- Harnad, Stevan (2004), "The Annotation Game: On Turing (1950) on Computing, Machinery, and Intelligence", in Epstein, Robert; Peters, Grace (eds.), The Turing Test Sourcebook: Philosophical and Methodological Issues in the Quest for the Thinking Computer, Klewer
- Haugeland, John (1985), Artificial Intelligence: The Very Idea, Cambridge, Massachusetts: MIT Press.
- Hayes, Patrick; Ford, Kenneth (1995), "Turing Test Considered Harmful", Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence (IJCAI95-1), Montreal, Quebec, Canada.: 972–997
- Heil, John (1998), Zihin Felsefesi: Çağdaş Bir Giriş, Londra ve New York: Routledge, ISBN 978-0-415-13060-8
- Hinshelwood, R.D. (2001), Group Mentality and Having a Mind: Reflections on Bion's work on groups and on psychosis
- Kurzweil, Ray (1990), Akıllı Makineler Çağı, Cambridge, Massachusetts: MIT Press, ISBN 978-0-262-61079-7
- Kurzweil, Ray (2005), Tekillik Yakında, Penguin Books, ISBN 978-0-670-03384-3
- Loebner, Hugh Gene (1994), "In response", ACM'nin iletişimi, 37 (6): 79–82, doi:10.1145/175208.175218, S2CID 38428377, alındı 22 Mart 2008
- McCorduck, Pamela (2004), Düşünen Makineler (2. baskı), Natick, MA: A. K. Peters, Ltd., ISBN 1-56881-205-1
- Moor, James, ed. (2003), Turing Testi: Yapay Zekanın Zorlu Standardı, Dordrecht: Kluwer Academic Publishers, ISBN 978-1-4020-1205-1
- Penrose, Roger (1989), The Emperor's New Mind: Concerning Computers, Minds, and The Laws of Physics, Oxford University Press, ISBN 978-0-14-014534-2
- Russell, Stuart; Norvig, Peter (2003) [1995]. Yapay Zeka: Modern Bir Yaklaşım (2. baskı). Prentice Hall. ISBN 978-0137903955.
- Russell, Stuart J .; Norvig, Peter (2010), Yapay Zeka: Modern Bir Yaklaşım (3rd ed.), Upper Saddle River, NJ: Prentice Hall, ISBN 978-0-13-604259-4
- Saygın, A. P .; Çiçekli, I .; Akman, V. (2000), "Turing Testi: 50 Yıl Sonra" (PDF), Akıllar ve Makineler, 10 (4): 463–518, doi:10.1023/A:1011288000451, hdl:11693/24987, S2CID 990084. Yeniden basıldı Moor (2003), sayfa 23–78).
- Saygın, A. P .; Cicekli, I. (2002), "Pragmatics in human-computer conversation", Pragmatik Dergisi, 34 (3): 227–258, CiteSeerX 10.1.1.12.7834, doi:10.1016/S0378-2166(02)80001-7.
- Saygin, A.P.; Roberts, Gary; Beber, Grace (2008), "Comments on "Computing Machinery and Intelligence" by Alan Turing", in Epstein, R.; Roberts, G .; Poland, G. (eds.), Parsing the Turing Test: Philosophical and Methodological Issues in the Quest for the Thinking Computer, Dordrecht, Netherlands: Springer, Bibcode:2009pttt.book.....E, doi:10.1007/978-1-4020-6710-5, ISBN 978-1-4020-9624-2, S2CID 60070108
- Searle, John (1980), "Minds, Brains and Programs", Davranış ve Beyin Bilimleri, 3 (3): 417–457, doi:10.1017/S0140525X00005756. Yukarıdaki sayfa numaraları bir standardı ifade eder pdf print of the article. Ayrıca bkz. Searle's orijinal taslak.
- Shah, Huma; Warwick, Kevin (2009a), "Emotion in the Turing Test: A Downward Trend for Machines in Recent Loebner Prizes", in Vallverdú, Jordi; Casacuberta, David (eds.), Handbook of Research on Synthetic Emotions and Sociable Robotics: New Applications in Affective Computing and Artificial Intelligence, Information Science, IGI, ISBN 978-1-60566-354-8
- Shah, Huma; Warwick, Kevin (June 2010), "Hidden Interlocutor Misidentification in Practical Turing Tests", Akıllar ve Makineler, 20 (3): 441–454, doi:10.1007/s11023-010-9219-6, S2CID 34076187
- Shah, Huma; Warwick, Kevin (April 2010), "Testing Turing's five minutes, parallel‐paired imitation game", Kybernetes, 4 (3): 449–465, doi:10.1108/03684921011036178
- Shapiro, Stuart C. (1992), "The Turing Test and the economist", ACM SIGART Bülteni, 3 (4): 10–11, doi:10.1145/141420.141423, S2CID 27079507
- Shieber, Stuart M. (1994), "Lessons from a Restricted Turing Test", ACM'nin iletişimi, 37 (6): 70–78, arXiv:cmp-lg/9404002, Bibcode:1994cmp.lg....4002S, CiteSeerX 10.1.1.54.3277, doi:10.1145/175208.175217, S2CID 215823854, alındı 25 Mart 2008
- Sterrett, S. G. (2000), "Turing's Two Test of Intelligence", Akıllar ve Makineler, 10 (4): 541, doi:10.1023/A:1011242120015, hdl:10057/10701, S2CID 9600264 (reprinted in The Turing Test: The Elusive Standard of Artificial Intelligence edited by James H. Moor, Kluwer Academic 2003) ISBN 1-4020-1205-5
- Sundman, John (26 February 2003), "Yapay aptallık", Salon.com, dan arşivlendi orijinal 7 Mart 2008'de, alındı 22 Mart 2008
- Thomas, Peter J. (1995), The Social and Interactional Dimensions of Human-Computer Interfaces, Cambridge University Press, ISBN 978-0-521-45302-8
- Swirski, Peter (2000), Edebiyat ve Bilim Arasında: Poe, Lem ve Estetik, Bilişsel Bilim ve Edebiyat Bilgisinde Keşifler, McGill-Queen's University Press, ISBN 978-0-7735-2078-3
- Traiger, Saul (2000), "Making the Right Identification in the Turing Test", Akıllar ve Makineler, 10 (4): 561, doi:10.1023/A:1011254505902, S2CID 2302024 (reprinted in The Turing Test: The Elusive Standard of Artificial Intelligence edited by James H. Moor, Kluwer Academic 2003) ISBN 1-4020-1205-5
- Turing, Alan (1948), "Machine Intelligence", Copeland, B. Jack (ed.), Temel Turing: Bilgisayar çağını doğuran fikirler, Oxford: Oxford University Press, ISBN 978-0-19-825080-7
- Turing, Alan (Ekim 1950), "Bilgi İşlem Makineleri ve İstihbarat", Zihin, LIX (236): 433–460, doi:10.1093 / zihin / LIX.236.433, ISSN 0026-4423
- Turing, Alan (1952), "Otomatik Hesaplama Makinelerinin Düşünmesi Söylenebilir mi?", Copeland, B. Jack (ed.), Temel Turing: Bilgisayar çağını doğuran fikirler, Oxford: Oxford University Press, ISBN 978-0-19-825080-7
- Zylberberg, A .; Calot, E. (2007), "Devlet Odaklı Alanlardaki Yalanları Genetik Algoritmalara Dayalı Olarak Optimize Etmek", Bildiriler VI Yazılım Mühendisliği Ibero-Amerikan Sempozyumu: 11–18, ISBN 978-9972-2885-1-7
- Weizenbaum, Joseph (Ocak 1966), "ELIZA - İnsan ve Makine Arasındaki Doğal Dil İletişiminin İncelenmesi İçin Bir Bilgisayar Programı", ACM'nin iletişimi, 9 (1): 36–45, doi:10.1145/365153.365168, S2CID 1896290
- Whitby, Blay (1996), "The Turing Test: AI's Biggest Blind Alley?", Millican, Peter; Clark, Andy (editörler), Makineler ve Düşünce: Alan Turing'in Mirası, 1, Oxford University Press, s. 53–62, ISBN 978-0-19-823876-8
daha fazla okuma
- Cohen, Paul R. (2006), "'Turing'in Testi Değilse Ne Olur? ", AI Dergisi, 26 (4).
- Marcus, Gary, "Ben İnsan mıyım ?: Araştırmacıların yapay zekayı doğal türden ayırt etmek için yeni yollara ihtiyacı var", Bilimsel amerikalı, cilt. 316, hayır. 3 (Mart 2017), s. 58–63. Çoklu Yapay zeka etkinliği testleri gereklidir, çünkü "tıpkı tek bir testin olmaması gibi atletik kahramanlık, nihai bir sınav olamaz zeka. "Böyle bir test, bir" İnşaat Zorluğu ", algıyı ve fiziksel eylemi test eder -" akıllı davranışın orijinal Turing testinde tamamen bulunmayan iki önemli öğesi. "Diğer bir öneri, makinelere aynı standartlaştırılmış bilim testlerini vermekti. ve okul çocuklarının aldığı diğer disiplinler. Yapay zeka için şimdiye kadar aşılması imkansız bir engel, güvenilirlik için yetersizliktir. belirsizliği giderme. "[V] irtually [insanların oluşturduğu] her cümle belirsiz, genellikle birden çok şekilde. "Önemli bir örnek" zamir belirsizliği giderme sorunu "olarak bilinir: bir makinenin kime veya neye karar vermesinin bir yolu yoktur. zamir cümle içinde - "o", "o" veya "o" gibi - ifade eder.
- Moor James H. (2001), "Turing Testinin Durumu ve Geleceği", Akıllar ve Makineler, 11 (1): 77–93, doi:10.1023 / A: 1011218925467, ISSN 0924-6495, S2CID 35233851.
- Warwick, Kevin ve Shah, Huma (2016), "Turing's Imitation Game: Conversations with the Unknown", Cambridge University Press.
Dış bağlantılar
- Turing Testi - Julian Wagstaff tarafından bir Opera
- Turing testi -de Curlie
- Turing Testi - Turing testi gerçekten ne kadar doğru olabilir?
- Zalta, Edward N. (ed.). "Turing testi". Stanford Felsefe Ansiklopedisi.
- Turing Testi: 50 Yıl Sonra 2000 yılı bakış açısından Turing Testi ile ilgili yarım yüzyıllık bir çalışmayı gözden geçiriyor.
- Kapor ve Kurzweil arasında bahis yapın kendi pozisyonlarının ayrıntılı gerekçeleri dahil.
- Turing Testi Neden Yapay Zekanın En Büyük Kör Sokağı Blay Witby tarafından
- Jabberwacky.com Bir AI gevezelik İnsanlardan öğrenen ve taklit eden
- New York Times makine zekası üzerine makaleler Bölüm 1 ve Bölüm 2
- ""Şimdiye kadarki ilk (kısıtlı) Turing testi "2. sezon, 5. bölüm". Scientific American Frontiers. Chedd-Angier Prodüksiyon Şirketi. 1991–1992. PBS. Arşivlendi 2006'daki orjinalinden.
- Bilgisayar Bilimleri Unplugged öğretim etkinliği Turing testi için.
- Wiki Haberleri: "Konuşma: Bilgisayar uzmanları A.L.I.C.E.'nin 10. doğum gününü kutluyor."
| Yetki kontrolü |
|---|