Hiyerarşik zamansal hafıza - Hierarchical temporal memory
Hiyerarşik zamansal hafıza (HTM) Numenta tarafından geliştirilen biyolojik olarak kısıtlanmış bir makine zekası teknolojisidir. İlk olarak 2004 kitabında tanımlanmıştır İstihbarat Üzerine tarafından Jeff Hawkins ile Sandra Blakeslee HTM, günümüzde öncelikle anomali tespiti veri akışında. Teknoloji dayanmaktadır sinirbilim ve fizyoloji ve etkileşimi piramidal nöronlar içinde neokorteks of memeli (özellikle, insan ) beyin.
HTM'nin merkezinde öğreniyoruz algoritmalar saklayabilen, öğrenebilen, anlam çıkarmak ve yüksek dereceli dizileri hatırlayın. Diğer çoğu makine öğrenimi yönteminin aksine, HTM sürekli olarak öğrenir (bir denetimsiz işlem) etiketlenmemiş verilerde zamana dayalı modeller. HTM, gürültüye karşı dayanıklıdır ve yüksek kapasiteye sahiptir (aynı anda birden fazla modeli öğrenebilir). Bilgisayarlara uygulandığında, HTM tahmin için çok uygundur,[1] anomali tespiti,[2] sınıflandırma ve nihayetinde sensorimotor uygulamaları.[3]
HTM, aşağıdaki örnek uygulamalar aracılığıyla yazılımda test edilmiş ve uygulanmıştır: Numenta ve Numenta'nın ortaklarından birkaç ticari uygulama.
Yapı ve algoritmalar
Tipik bir HTM ağı, ağaç şeklinde hiyerarşi seviyeleri ("ile karıştırılmamalıdır"katmanlar" neokorteks, tarif edildiği gibi altında ). Bu seviyeler, adı verilen daha küçük unsurlardan oluşur bölges (veya düğümler). Hiyerarşideki tek bir seviye muhtemelen birkaç bölge içerir. Daha yüksek hiyerarşi seviyelerinin genellikle daha az bölgesi vardır. Daha yüksek hiyerarşi seviyeleri, daha karmaşık kalıpları ezberlemek için bunları birleştirerek daha düşük seviyelerde öğrenilen kalıpları yeniden kullanabilir.
Her HTM bölgesi aynı temel işleve sahiptir. Öğrenme ve çıkarım modlarında, duyusal veriler (örneğin gözlerden gelen veriler) alt düzey bölgelere gelir. Üretim modunda, en alt seviye bölgeler, belirli bir kategorinin oluşturulmuş modelini verir. En üst düzey genellikle en genel ve en kalıcı kategorileri (kavramları) depolayan tek bir bölgeye sahiptir; bunlar daha düşük seviyelerde daha küçük kavramları belirler veya bunlar tarafından belirlenir - zaman ve mekan açısından daha kısıtlı olan kavramlar[açıklama gerekli ]. Çıkarım modunda ayarlandığında, bir bölge (her seviyede) "alt" bölgelerinden gelen bilgileri bellekte sahip olduğu kategorilerin olasılıkları olarak yorumlar.
Her HTM bölgesi, uzamsal kalıpları - genellikle aynı anda oluşan girdi bitlerinin kombinasyonlarını - tanımlayarak ve ezberleyerek öğrenir. Ardından, birbiri ardına meydana gelmesi muhtemel olan uzaysal modellerin zamansal dizilerini tanımlar.
Gelişen bir model olarak
HTM, Jeff Hawkins Bin Beyin Zeka Teorisi. Dolayısıyla, neokorteks üzerindeki yeni bulgular, zamanla yanıt olarak değişen HTM modeline aşamalı olarak dahil edilir. Yeni bulgular, modelin önceki bölümlerini geçersiz kılmaz, bu nedenle bir nesilden gelen fikirler, birbirini izleyen nesilde mutlaka hariç tutulmaz. Teorinin gelişen doğası nedeniyle, birkaç nesil HTM algoritmaları olmuştur,[4] aşağıda kısaca açıklanmıştır.
Birinci nesil: zeta 1
İlk nesil HTM algoritmaları bazen şu şekilde anılır: zeta 1.
Eğitim
Sırasında Eğitimbir düğüm (veya bölge), girdi olarak uzaysal modellerin zamansal bir dizisini alır. Öğrenme süreci iki aşamadan oluşur:
- mekansal havuzlama (girdide) sık gözlemlenen kalıpları tanımlar ve bunları "tesadüfler" olarak ezberler. Birbirine önemli ölçüde benzeyen modeller aynı tesadüf olarak değerlendirilir. Çok sayıda olası girdi örüntüsü, yönetilebilir sayıda bilinen tesadüflere indirgenmiştir.
- geçici havuz eğitim sırasında birbirini takip etmesi muhtemel tesadüfleri zamansal gruplara ayırır. Her kalıp grubu, giriş modelinin (veya "ad" ın "nedenini" temsil eder. İstihbarat Üzerine).
Kavramları mekansal havuzlama ve geçici havuz mevcut HTM algoritmalarında hala oldukça önemlidir. Zamansal havuzlama henüz tam olarak anlaşılmamıştır ve anlamı zamanla değişmiştir (HTM algoritmaları geliştikçe).
Çıkarım
Sırasında çıkarımdüğüm, bir modelin bilinen her bir tesadüfe ait olduğu olasılıklar kümesini hesaplar. Daha sonra girdinin her bir zamansal grubu temsil etme olasılıklarını hesaplar. Gruplara atanan olasılıklar kümesi, bir düğümün giriş örüntüsü hakkındaki "inancı" olarak adlandırılır. (Basitleştirilmiş bir uygulamada, düğümün inancı yalnızca bir kazanan gruptan oluşur). Bu inanç, hiyerarşinin bir sonraki daha yüksek seviyesindeki bir veya daha fazla "ana" düğüme iletilen çıkarımın sonucudur.
Düğüme yönelik "beklenmeyen" örüntülerin herhangi bir geçici gruba ait olma olasılıkları baskın değildir, ancak birkaç gruba ait olma olasılıkları neredeyse eşittir. Kalıp dizileri eğitim dizilerine benziyorsa, gruplara atanan olasılıklar örüntüler alındıkça değişmeyecektir. Düğümün çıktısı çok fazla değişmeyecek ve zaman içinde bir çözünürlük[açıklama gerekli ] kayıp.
Daha genel bir şemada, düğümün inancı herhangi bir düzeydeki herhangi bir düğümün girişine gönderilebilir, ancak düğümler arasındaki bağlantılar hala sabittir. Daha yüksek seviyeli düğüm, bu çıktıyı diğer alt düğümlerden gelen çıktıyla birleştirerek kendi girdi modelini oluşturur.
Yukarıda açıklandığı gibi her düğümde uzay ve zamandaki çözünürlük kaybolduğundan, daha yüksek seviyeli düğümler tarafından oluşturulan inançlar daha da geniş bir uzay ve zaman aralığını temsil eder. Bu, insan beyni tarafından algılandığı şekliyle fiziksel dünyanın organizasyonunu yansıtmak içindir. Daha büyük kavramların (ör. Nedenler, eylemler ve nesneler) daha yavaş değiştiği algılanır ve daha hızlı değişen daha küçük kavramlardan oluşur. Jeff Hawkins, beyinlerin bu tür bir hiyerarşiyi dış dünyanın organizasyonuyla eşleşecek, tahmin edecek ve etkileyecek şekilde geliştirdiğini öne sürüyor.
Zeta 1 HTM'nin işleyişi hakkında daha fazla ayrıntı Numenta'nın eski belgelerinde bulunabilir.[5]
İkinci nesil: kortikal öğrenme algoritmaları
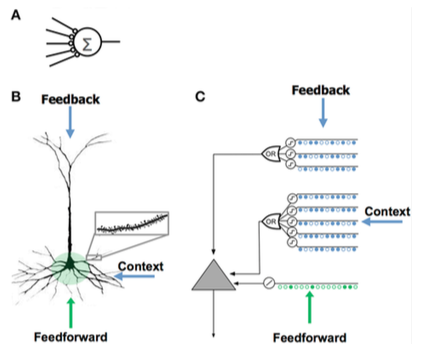
Genellikle kortikal öğrenme algoritmaları (CLA) olarak adlandırılan ikinci nesil HTM öğrenme algoritmaları, zeta 1'den büyük ölçüde farklıydı. veri yapısı aranan seyrek dağıtılmış temsiller (yani, elemanları ikili, 1 veya 0 olan ve 1 bit sayısı 0 bit sayısına kıyasla küçük olan bir veri yapısı) ve daha biyolojik olarak gerçekçi bir nöron modelini (genellikle de gibi hücreHTM bağlamında).[6] Bu HTM neslinde iki temel bileşen vardır: a mekansal havuzlama algoritma[7] hangi çıktılar seyrek dağıtılmış temsiller (SDR) ve a sıra belleği algoritma[8] karmaşık dizileri temsil etmeyi ve tahmin etmeyi öğrenir.
Bu yeni nesilde, katmanlar ve mini sütunlar of beyin zarı ele alınmış ve kısmen modellenmiştir. Her HTM katmanı (açıklandığı gibi bir HTM hiyerarşisinin HTM seviyesiyle karıştırılmamalıdır) yukarıda ) birbiriyle yüksek oranda bağlantılı bir dizi mini sütundan oluşur. Bir HTM katmanı, girişinden seyrek dağıtılmış bir temsil oluşturur, böylece sabit bir yüzde mini sütunlar herhangi bir zamanda aktif[açıklama gerekli ]. Bir mini sütun, aynı özelliklere sahip bir hücre grubu olarak anlaşılır. alıcı alan. Her mini sütunun, önceki birkaç durumu hatırlayabilen birkaç hücre vardır. Bir hücre şu üç durumdan birinde olabilir: aktif, inaktif ve tahmini durum.
Mekansal havuzlama
Her bir mini sütunun alıcı alanı, çok daha fazla sayıda düğüm girişinden rastgele seçilen sabit sayıda girdidir. (Spesifik) giriş modeline bağlı olarak, bazı mini sütunlar az çok aktif giriş değerleriyle ilişkilendirilecektir. Mekansal havuzlama nispeten sabit bir sayıda en aktif mini kolonları seçer ve aktif olanların yakınındaki diğer mini kolonları inaktive eder (inhibe eder). Benzer girdi kalıpları, kararlı bir mini sütun kümesini etkinleştirme eğilimindedir. Her katman tarafından kullanılan bellek miktarı, daha karmaşık uzamsal kalıpları öğrenmek için artırılabilir veya daha basit kalıpları öğrenmek için azaltılabilir.
Aktif, pasif ve tahmini hücreler
Yukarıda bahsedildiği gibi, bir mini sütunun bir hücresi (veya bir nöronu) herhangi bir zamanda aktif, pasif veya tahmini bir durumda olabilir. Başlangıçta hücreler etkisizdir.
Hücreler nasıl aktif hale gelir?
Etkin mini sütundaki bir veya daha fazla hücre, tahmini durum (aşağıya bakın), mevcut zaman adımında aktif hale gelen tek hücreler olacaktır. Etkin mini sütundaki hücrelerin hiçbiri tahmin durumunda değilse (bu, ilk zaman adımı sırasında veya bu mini sütunun etkinleştirilmesi beklenmediğinde gerçekleşir), tüm hücreler etkinleştirilir.
Hücreler nasıl tahmine dayalı hale gelir?
Bir hücre aktif hale geldiğinde, daha önceki birkaç adımda aktif olma eğiliminde olan yakındaki hücrelere kademeli olarak bağlantılar oluşturur. Böylece bir hücre, bağlı hücrelerin aktif olup olmadığını kontrol ederek bilinen bir diziyi tanımayı öğrenir. Çok sayıda bağlı hücre etkinse, bu hücre tahmini dizinin sonraki birkaç girdisinden birinin beklentisiyle durumu.
Bir mini sütunun çıktısı
Bir katmanın çıktısı, hem etkin hem de tahmini durumlarda mini sütunları içerir. Bu nedenle, mini sütunlar uzun süreler boyunca aktiftir ve bu, ana katman tarafından görülen daha büyük bir zamansal kararlılığa yol açar.
Çıkarım ve çevrimiçi öğrenme
Kortikal öğrenme algoritmaları her yeni giriş modelinden sürekli olarak öğrenebilir, bu nedenle ayrı bir çıkarım moduna gerek yoktur. Çıkarım sırasında HTM, giriş akışını önceden öğrenilen dizilerin parçalarıyla eşleştirmeye çalışır. Bu, her bir HTM katmanının, tanınan dizilerin olası devamını sürekli olarak tahmin etmesini sağlar. Tahmin edilen dizinin indeksi, katmanın çıktısıdır. Tahminler, girdi modellerinden daha az sıklıkla değişme eğiliminde olduğundan, bu, daha yüksek hiyerarşi seviyelerinde çıktının zamansal istikrarının artmasına yol açar. Tahmin aynı zamanda dizideki eksik kalıpları doldurmaya ve sistemi tahmin ettiği sonucu çıkarması için önyargılı olarak belirsiz verileri yorumlamaya yardımcı olur.
CLA'ların uygulamaları
Kortikal öğrenme algoritmaları şu anda ticari olarak sunuluyor SaaS Numenta tarafından (Grok gibi[9]).
CLA'ların geçerliliği
Eylül 2011'de, kortikal öğrenme algoritmalarıyla ilgili olarak Jeff Hawkins'e şu soru yöneltildi: "Modelde yaptığınız değişikliklerin iyi olup olmadığını nasıl anlarsınız?" Jeff'in cevabı "Cevap için iki kategori var: biri sinirbilime bakmak, diğeri ise makine zekası için yöntemler. Sinirbilim dünyasında yapabileceğimiz birçok tahmin var ve bunlar test edilebilir. Teorilerimiz çok çeşitli nörobilim gözlemlerini açıklarsa, bize doğru yolda olduğumuzu söyler.Makine öğrenimi dünyasında, onlar bunu umursamıyorlar, sadece pratik problemlerde ne kadar iyi çalıştığını önemsiyorlar. Daha önce kimsenin çözemediği bir sorunu çözebildiğiniz ölçüde, insanlar bunu dikkate alacaktır. "[10]
Üçüncü nesil: sensorimotor çıkarım
Üçüncü nesil, ikinci nesil üzerine inşa edilir ve neokortekste bir sensörimotor çıkarım teorisi ekler.[11][12] Bu teori şunu önermektedir: kortikal sütunlar Hiyerarşinin her seviyesinde, zaman içinde nesnelerin tam modellerini öğrenebilir ve bu özelliklerin nesneler üzerindeki belirli konumlarda öğrenilmesi. Teori 2018'de genişletildi ve Bin Beyin Teorisi olarak anıldı.[13]
Nöron modellerinin karşılaştırılması
Nöron Modellerinin Karşılaştırılması Yapay Sinir Ağı (YSA) Neocortical Piramidal Nöron (Biyolojik Nöron ) HTM Modeli Nöron[8] - Birkaç sinaps
- Dendrit yok
- Toplam girdi × ağırlıklar
- Sinapsların ağırlıklarını değiştirerek öğrenir
- Binlerce sinapslar üzerinde dendritler
- Aktif dendritler: hücre yüzlerce benzersiz kalıbı tanır
- Bir dendritik segment üzerindeki bir dizi sinapsın birlikte aktivasyonu, NMDA başak[açıklama gerekli ] ve depolarizasyon[açıklama gerekli ] -de Soma
- Hücreye girdi kaynakları:
- Sinaps oluşturan ileri beslemeli girişler yakın soma'ya ve doğrudan yol açar aksiyon potansiyalleri
- NMDA artışları daha fazla uzak baz alınan[açıklama gerekli ]
- Apikal somayı depolarize eden dendritler (genellikle somatik bir aksiyon potansiyeli oluşturmak için yeterli değildir)
- Yeni sinapslar geliştirerek öğrenir
- Neokorteks katman 2/3 ve 5'teki piramidal hücrelerden esinlenilmiştir.
- Binlerce sinaps
- Aktif dendritler: hücre yüzlerce benzersiz kalıbı tanır
- Model dendritler ve NMDA sivri uçları, bir dizi sinaps içeren her bir çakışma dedektörü dizisi ile
- Yeni sinapsların büyümesini modelleyerek öğrenir
HTM ve neokorteksi karşılaştırmak
HTM, neokorteksteki hiyerarşik olarak ilişkili bir kortikal bölge grubunun özelliği olan işlevselliği uygulamaya çalışır. Bir bölge neokorteksin% 'si bir veya daha fazla seviyeleri HTM hiyerarşisinde, hipokamp uzaktan en yüksek HTM düzeyine benzer. Tek bir HTM düğümü, bir grup kortikal sütunlar belirli bir bölge içinde.
Öncelikle işlevsel bir model olmasına rağmen, HTM'nin algoritmalarını neokorteks katmanlarındaki nöronal bağlantıların yapısı ile ilişkilendirmek için birkaç girişimde bulunulmuştur.[14][15] Neokorteks, 6 yatay katmandan oluşan dikey sütunlarda düzenlenmiştir. Neokorteksteki 6 hücre katmanı, HTM hiyerarşisindeki düzeylerle karıştırılmamalıdır.
HTM düğümleri, kolon başına yaklaşık 20 HTM "hücre" ile kortikal kolonların bir kısmını (80 ila 100 nöron) modellemeye çalışır. HTM'ler, uzamsal "havuzlama" için katman 2'de sütun başına 1 hücre ve geçici havuzlama için katman 3'te sütun başına 1 ila 2 düzine girişin uzamsal ve zamansal özelliklerini algılamak için yalnızca 2. ve 3. katmanları modellemektedir. HTM'lerin ve korteksin anahtarlarından biri, herhangi bir zamanda sütunların sadece yaklaşık% 2'sinin aktif olduğu bir "seyrek dağıtım gösterimi" kullanmanın bir sonucu olan girdideki gürültü ve varyasyonla başa çıkma yetenekleridir.
Bir HTM, korteksin öğrenmesinin ve esnekliğinin bir bölümünü yukarıda açıklandığı gibi modellemeye çalışır. HTM'ler ve nöronlar arasındaki farklar şunları içerir:[16]
- kesinlikle ikili sinyaller ve sinapslar
- sinapsların veya dendritlerin doğrudan engellenmesi yok (ancak dolaylı olarak simüle edildi)
- şu anda yalnızca 2/3 ve 4. katmanları modeller (5 veya 6 değil)
- "motor" kontrolü yok (katman 5)
- bölgeler arasında geri besleme yok (yüksek katman 6 ila düşük katman 1)
Seyrek dağıtılmış temsiller
Bellek bileşenini sinir ağlarıyla entegre etmenin, dağıtılmış temsillerdeki erken araştırmalara kadar uzanan uzun bir geçmişi vardır.[17][18] ve kendi kendini düzenleyen haritalar. Örneğin, seyrek dağıtılmış bellek (SDM), sinir ağları tarafından kodlanan modeller için hafıza adresleri olarak kullanılır. içerik adreslenebilir bellek "nöronlar" esasen adres kodlayıcılar ve kod çözücüler olarak hizmet eder.[19][20]
Bilgisayarlar bilgileri şurada depolar: yoğun 32 bit gibi temsiller kelime, tüm 1 ve 0 kombinasyonlarının mümkün olduğu. Aksine, beyinler seyrek dağıtılmış temsiller (SDR'ler).[21] İnsan neokorteksinde yaklaşık 16 milyar nöron bulunur, ancak herhangi bir zamanda yalnızca küçük bir yüzde aktiftir. Nöronların aktiviteleri bilgisayardaki bitler gibidir ve bu nedenle gösterim seyrektir. Benzer SDM tarafından geliştirilmiş NASA 80'lerde[19] ve vektör alanı kullanılan modeller Gizli anlamsal analiz HTM, seyrek dağıtılmış gösterimler kullanır.[22]
HTM'de kullanılan SDR'ler, aktif bitlerin küçük bir yüzdesi (1s) ile birçok bitten oluşan verilerin ikili temsilleridir; tipik bir uygulamada 2048 sütun ve 64K yapay nöron olabilir ve 40 kadar azı aynı anda aktif olabilir. Verilen herhangi bir gösterimde bitlerin çoğunun "kullanılmadan" gitmesi daha az verimli görünse de, SDR'lerin geleneksel yoğun temsillere göre iki büyük avantajı vardır. İlk olarak, SDR'ler, paylaşılan temsilin anlamı nedeniyle yolsuzluğa ve belirsizliğe toleranslıdır (dağıtılmış) küçük bir yüzde üzerinden (seyrek) aktif bit. Yoğun bir gösterimde, tek bir biti çevirmek anlamı tamamen değiştirirken, bir SDR'de tek bir bit genel anlamı çok fazla etkilemeyebilir. Bu, SDR'lerin ikinci avantajına yol açar: bir temsilin anlamı tüm aktif bitlere dağıtıldığı için, iki temsil arasındaki benzerlik, bir ölçüsü olarak kullanılabilir. anlamsal temsil ettikleri nesnelerdeki benzerlik. Yani, bir SDR'deki iki vektör aynı pozisyonda 1'lere sahipse, o zaman bunlar bu öznitelikte anlamsal olarak benzerdir. SDR'lerdeki bitlerin anlamsal anlamı vardır ve bu anlam bitler arasında dağıtılır.[22]
anlamsal katlama teori[23] kelimelerin kelime-SDR'lere kodlandığı ve terimler, cümleler ve metinler arasındaki benzerliğin basit uzaklık ölçüleriyle hesaplanabildiği, dil anlambilimi için yeni bir model önermek için bu SDR özelliklerini temel alır.
Diğer modellere benzerlik
Bayes ağları
Bir Bayes ağı bir HTM, ağaç şeklindeki bir hiyerarşi içinde düzenlenen bir düğümler koleksiyonunu içerir. Hiyerarşideki her düğüm, aldığı giriş modellerinde ve zamansal dizilerde bir dizi nedeni keşfeder. Bayes inanç revizyonu algoritması, ileri besleme ve geribildirim inançlarını çocuktan ana düğümlere ve tersi yönde yaymak için kullanılır. Bununla birlikte, Bayes ağlarına benzetme sınırlıdır, çünkü HTM'ler kendi kendine eğitilebilir (öyle ki her düğümün kesin bir aile ilişkisi vardır), zamana duyarlı verilerle başa çıkabilir ve gizli dikkat.
Bayesian'a dayalı bir hiyerarşik kortikal hesaplama teorisi inanç yayılımı Tai Sing Lee tarafından daha önce önerilmişti ve David Mumford.[24] HTM çoğunlukla bu fikirlerle tutarlı olsa da, görsel kortekste değişmeyen temsillerin işlenmesi hakkında ayrıntılar ekler.[25]
Nöral ağlar
Neokorteksin ayrıntılarını modelleyen herhangi bir sistem gibi, HTM bir yapay sinir ağı. HTM'lerde yaygın olarak kullanılan ağaç şeklindeki hiyerarşi, geleneksel sinir ağlarının olağan topolojisine benzer. HTM'ler kortikal kolonları (80 ila 100 nöron) ve bunların daha az HTM "nöronları" ile etkileşimlerini modellemeye çalışır. Mevcut HTM'lerin amacı, nöronların ve ağın (şu anda anlaşıldıkları gibi) işlevlerinin çoğunu tipik bilgisayarların kapasitesi dahilinde ve görüntü işleme gibi kolayca kullanışlı hale getirilebilecek alanlarda yakalamaktır. Örneğin, daha yüksek seviyelerden ve motor kontrolünden geri besleme yapılmaya çalışılmaz, çünkü bunların nasıl birleştirileceği henüz anlaşılmamıştır ve mevcut HTM yeteneklerinde yeterli oldukları belirlendiğinden değişken sinapslar yerine ikili kullanılır.
LAMINART ve benzeri sinir ağları tarafından araştırılan Stephen Grossberg Nörofizyolojik ve psikofiziksel verileri açıklamak için hem korteksin altyapısını hem de nöronların davranışını zamansal bir çerçevede modellemeye çalışın. Ancak, bu ağlar şu anda gerçekçi uygulama için çok karmaşıktır.[26]
HTM aynı zamanda Tomaso Poggio modelleme yaklaşımı dahil ventral akım HMAX olarak bilinen görsel korteksin. HTM'nin çeşitli AI fikirlerine olan benzerlikleri, Yapay Zeka dergisinin Aralık 2005 sayısında açıklanmaktadır.[27]
Neocognitron
Neocognitron Profesör tarafından önerilen hiyerarşik çok katmanlı bir sinir ağı Kunihiko Fukushima 1987'de ilklerden biridir Derin Öğrenme Sinir Ağları modelleri.[28]
NuPIC platformu ve geliştirme araçları
Numenta Akıllı Bilgi İşlem Platformu (NuPIC) mevcut birkaç taneden biri HTM uygulamaları. Bazıları tarafından sağlanır Numenta bazıları tarafından geliştirilip sürdürülürken HTM açık kaynak topluluğu.
NuPIC, hem C ++ hem de Python'da Uzamsal Havuzlama ve Geçici Bellek uygulamalarını içerir. Ayrıca şunları içerir: 3 API. Kullanıcılar, HTM sistemlerinin doğrudan uygulamalarını kullanarak algoritmalar veya kullanarak bir Ağ oluşturun Ağ API, farklı korteks katmanları arasında karmaşık ilişkiler kurmak için esnek bir çerçeve.
NuPIC 1.0 Temmuz 2017'de piyasaya sürüldü ve ardından kod tabanı bakım moduna alındı. Numenta'da güncel araştırmalar devam ediyor araştırma kod tabanları.
Başvurular
NuPIC kullanılarak aşağıdaki ticari uygulamalar mevcuttur:
- Grok - BT sunucuları için anormallik algılama, bkz. www.grokstream.com
- Cortical.io - gelişmiş doğal dil işleme, bkz. www.cortical.io
NuPIC'de aşağıdaki araçlar mevcuttur:
- HTM Studio - kendi verilerinizi kullanarak zaman serilerindeki anormallikleri bulun, bkz. numenta.com/htm-studio/
- Numenta Anomali Benchmark - HTM anomalilerini diğer anormallik tespit teknikleriyle karşılaştırın, bkz. numenta.com/numenta-anomaly-benchmark/
Aşağıdaki örnek uygulamalar NuPIC'de mevcuttur, bkz. numenta.com/applications/:
- Hisse senetleri için HTM - borsadaki anormallikleri izleme örneği (örnek kod)
- Sahte davranış tespiti - insan davranışındaki anormallikleri bulma örneği (teknik inceleme ve örnek kod)
- Jeo-uzamsal izleme - uzay ve zamanda hareket eden hedeflerdeki anormallikleri bulma örneği (teknik inceleme ve örnek kod)
Ayrıca bakınız
- Neocognitron
- Derin öğrenme
- Evrişimli sinir ağı
- Güçlü AI
- Yapay bilinç
- Bilişsel mimari
- İstihbarat Üzerine
- Bellek tahmin çerçevesi
- İnanç revizyonu
- İnanç yayılımı
- Biyonik
- Yapay zeka projelerinin listesi
- Hafıza Ağı
- Nöral Turing Makinesi
- Çoklu izleme teorisi
İlgili modeller
Referanslar
- ^ Cui, Yuwei; Ahmad, Subutai; Hawkins, Jeff (2016). "Denetimsiz Sinir Ağı Modeli ile Sürekli Çevrimiçi Sıralı Öğrenme". Sinirsel Hesaplama. 28 (11): 2474–2504. arXiv:1512.05463. doi:10.1162 / NECO_a_00893. PMID 27626963.
- ^ Ahmad, Subutai; Lavin, İskender; Purdy, Scott; Agha, Zuha (2017). "Veri akışı için denetimsiz gerçek zamanlı anormallik tespiti". Nöro hesaplama. 262: 134–147. doi:10.1016 / j.neucom.2017.04.070.
- ^ "Duyusal motor çıkarım üzerine yeni teori çalışması hakkında ön ayrıntılar". HTM Forumu. 2016-06-03.
- ^ HTM Geriye Dönük açık Youtube
- ^ "Numenta eski belgeler". numenta.com. Arşivlenen orijinal 2009-05-27 tarihinde.
- ^ Kortikal öğrenme algoritmalarını açıklayan Jeff Hawkins dersi açık Youtube
- ^ Cui, Yuwei; Ahmad, Subutai; Hawkins, Jeff (2017). "HTM Uzamsal Pooler - Çevrimiçi Seyrek Dağıtılmış Kodlama için Neokortikal Algoritma". Hesaplamalı Sinirbilimde Sınırlar. 11: 111. doi:10.3389 / fncom.2017.00111. PMC 5712570. PMID 29238299.
- ^ a b Hawkins, Jeff; Ahmad, Subutai (30 Mart 2016). "Nöronlarda Neden Binlerce Sinaps Var, Neocortex'te Sıralı Bellek Teorisi". Ön. Sinir Devreleri. 10: 23. doi:10.3389 / fncir.2016.00023. PMC 4811948. PMID 27065813.
- ^ "Grok Ürün Sayfası". grokstream.com.
- ^ Laserson, Jonathan (Eylül 2011). "Sinir Ağlarından Derin Öğrenmeye: İnsan Beynini Sıfırlamak" (PDF). XRDS. 18 (1). doi:10.1145/2000775.2000787.
- ^ Hawkins, Jeff; Ahmad, Subutai; Cui, Yuwei (2017). "Neocortex'teki Sütunların Dünyanın Yapısını Öğrenmeyi Nasıl Sağladığına Dair Bir Teori". Sinir Devrelerinde Sınırlar. 11: 81. doi:10.3389 / fncir.2017.00081. PMC 5661005. PMID 29118696.
- ^ Neocortex'in Yaptıklarının Yarısını Kaçırdık mı? Algının Temeli Olarak Alosantrik Konum açık Youtube
- ^ "Numenta, zeka ve kortikal hesaplama için çığır açan bir teori yayınladı". eurekalert.org. 2019-01-14.
- ^ Hawkins, Jeff; Blakeslee, Sandra. İstihbarat Üzerine.
- ^ George, Dileep; Hawkins, Jeff (2009). "Kortikal Mikro Devrelerin Matematiksel Teorisine Doğru". PLOS Hesaplamalı Biyoloji. 5 (10): e1000532. doi:10.1371 / journal.pcbi.1000532. PMID 19816557.
- ^ "HTM Kortikal Öğrenme Algoritmaları" (PDF). numenta.org.
- ^ Hinton, Geoffrey E. (1984). "Dağıtılmış temsiller". Arşivlenen orijinal 2017-11-14 tarihinde. Alıntı dergisi gerektirir
| günlük =(Yardım) - ^ Plaka, Tony (1991). "Holografik İndirgenmiş Gösterimler: Kompozisyonel Dağıtılmış Gösterimler için Evrişim Cebiri" (PDF). IJCAI.
- ^ a b Kanerva, Pentti (1988). Seyrek dağıtılmış bellek. MIT basın.
- ^ Snaider, Javier; Franklin, Stan (2012). Tamsayı seyrek dağıtılmış bellek (PDF). Yirmi beşinci uluslararası yetenek konferansı.
- ^ Olshausen, Bruno A .; Alan, David J. (1997). "Aşırı tamamlanmış bir temel kümesiyle seyrek kodlama: V1 tarafından kullanılan bir strateji?". Vizyon Araştırması. 37 (23): 3311–3325. doi:10.1016 / S0042-6989 (97) 00169-7. PMID 9425546.
- ^ a b Ahmad, Subutai; Hawkins, Jeff (2016). "Numenta NUPIC - seyrek dağıtılmış temsiller". arXiv:1601.00720 [q-bio.NC ].
- ^ De Sousa Webber, Francisco (2015). "Anlamsal Katlama Teorisi ve Anlamsal Parmak İzinde Uygulaması". arXiv:1511.08855 [cs.AI ].
- ^ Lee, Tai Sing; Mumford, David (2002). "Görsel Kortekste Hiyerarşik Bayesci Çıkarım". Amerika Optik Derneği Dergisi. A, Optik, Görüntü Bilimi ve Görme. 20 (7): 1434–48. CiteSeerX 10.1.1.12.2565. doi:10.1364 / josaa.20.001434. PMID 12868647.
- ^ George, Dileep (2010-07-24). "Görsel kortekste hiyerarşik Bayesci çıkarım". dileepgeorge.com. Arşivlenen orijinal 2019-08-01 tarihinde.
- ^ Grossberg, Stephen (2007). Cisek, Paul; Drew, Trevor; Kalaska, John (editörler). Birleşik bir neokorteks teorisine doğru: Görme ve biliş için laminer kortikal devreler. Teknik Rapor CAS / CNS-TR-2006-008. Hesaplamalı Sinirbilim İçin: Nöronlardan Teoriye ve Tekrar Tekrar (PDF) (Bildiri). Amsterdam: Elsevier. s. 79–104. Arşivlenen orijinal (PDF) 2017-08-29 tarihinde.
- ^ "ScienceDirect - Yapay Zeka". 169 (2). Aralık 2005: 103–212. Alıntı dergisi gerektirir
| günlük =(Yardım) - ^ Fukushima, Kunihiko (2007). "Neocognitron". Scholarpedia. 2: 1717. doi:10.4249 / bilim adamı. 1717.
Dış bağlantılar
Resmi
- Kortikal Öğrenme Algoritmasına genel bakış (Erişim tarihi Mayıs 2013)
- HTM Kortikal Öğrenme Algoritmaları (PDF Eylül 2011)
- Numenta, Inc.
- HTM Kortikal Öğrenme Algoritmaları Arşivi
- Computing Machinery Derneği, Numenta'dan Subutai Ahmad'ın 2009 tarihli konuşması
- OnIntelligence.org Forumu, bir İnternet forumu özellikle ilgili konuların tartışılması için Modeller ve Simülasyon Konuları forum.
- Hiyerarşik Zamansal Bellek (Microsoft PowerPoint sunusu)
- Kortikal Öğrenme Algoritması Eğitimi: CLA Temelleri HTM modeli tarafından kullanılan kortikal öğrenme algoritması (CLA) hakkında konuşun Youtube
Diğer
- Hiyerarşik Zamansal Bellek ile Örüntü Tanıma Yazar: Davide Maltoni, Nisan 13, 2011
- Vicarious Başlangıç, Dileep George tarafından HTM'ye dayanıyor
- The Gartner Fellows: Jeff Hawkins Röportajı Tom Austin tarafından Gartner, 2 Mart 2006
- Emerging Tech: Jeff Hawkins yapay zekayı yeniden icat ediyor Debra D'Agostino ve Edward H. Baker tarafından, CIO Insight, 1 Mayıs 2006
- "Beynini bir mikroçipe koymak" Stefanie Olsen tarafından, CNET News.com, 12 Mayıs 2006
- "Düşünme Makinesi" Evan Ratliff tarafından, Kablolu, Mart 2007
- İnsan gibi düşün Jeff Hawkins, tarafından IEEE Spektrumu, Nisan 2007
- Neocortex - Bellek Tahmin Çerçevesi — Açık kaynak İle uygulama GNU Genel Kamu Lisansı
- Hiyerarşik Zamansal Bellek ile ilgili Makaleler ve Kitaplar