OPTICS algoritması - OPTICS algorithm - Wikipedia
| Bir dizinin parçası |
| Makine öğrenme ve veri madenciliği |
|---|
Makine öğrenimi mekanları |
Kümeleme yapısını belirlemek için sıralama noktaları (OPTİK) yoğunluk tabanlı bulmak için bir algoritmadır[1] kümeler mekansal verilerde. Mihael Ankerst, Markus M. Breunig tarafından sunulmuştur. Hans-Peter Kriegel ve Jörg Sander.[2]Temel fikri şuna benzer: DBSCAN,[3] ancak DBSCAN'ın en büyük zayıflıklarından birini ele alıyor: değişen yoğunluktaki verilerde anlamlı kümeleri tespit etme problemi. Bunu yapmak için, veritabanının noktaları (doğrusal olarak) sıralanır, öyle ki uzaysal olarak en yakın noktalar sıralamada komşu olur. Ek olarak, her iki noktanın da aynı kümeye ait olması için bir küme için kabul edilmesi gereken yoğunluğu temsil eden her nokta için özel bir mesafe kaydedilir. Bu bir dendrogram.
Temel fikir
Sevmek DBSCAN OPTICS iki parametre gerektirir: ε, dikkate alınacak maksimum mesafeyi (yarıçapı) açıklayan ve DAKİKA, bir küme oluşturmak için gereken nokta sayısını açıklar. Bir nokta p bir çekirdek nokta en azından DAKİKA noktaları içinde bulunur ε-Semt (nokta dahil p kendisi). Kıyasla DBSCAN OPTICS ayrıca daha yoğun şekilde paketlenmiş bir kümenin parçası olan noktaları da dikkate alır, böylece her noktaya bir çekirdek mesafesi mesafeyi tanımlayan DAKİKAen yakın nokta:


ulaşılabilirlik mesafesi başka bir noktanın Ö bir noktadan p ya arasındaki mesafe Ö ve pveya çekirdek mesafesi p, hangisi daha büyükse:

Eğer p ve Ö en yakın komşular, bu sahip olduğumuzu varsaymalıyız p ve Ö aynı kümeye aittir.

Hem çekirdek mesafesi hem de ulaşılabilirlik mesafesi, yeterince yoğun bir küme yoksa (w.r.t. ε) kullanılabilir. Yeterince büyük bir ε, bu asla olmaz, ama sonra her ε-neighbourhood sorgusu tüm veritabanını döndürür ve sonuçta Çalışma süresi. Bu nedenle, ε parametresi, artık ilginç olmayan kümelerin yoğunluğunu kesmek ve algoritmayı hızlandırmak için gereklidir.

Parametre ε kesinlikle gerekli değil. Basitçe mümkün olan maksimum değere ayarlanabilir. Uzamsal bir indeks mevcut olduğunda, ancak, karmaşıklık açısından pratik bir rol oynar. OPTICS özetleri DBSCAN'dan bu parametreyi kaldırarak, en azından sadece maksimum değeri vermek zorunda kalacak şekilde.
Sözde kod
OPTICS'in temel yaklaşımı şuna benzer: DBSCAN, ancak bir dizi bilinen, ancak şimdiye kadar işlenmemiş küme üyelerini korumak yerine, bir öncelik sırası (ör. dizine alınmış bir yığın ) kullanıldı.
işlevi OPTİK (DB, eps, Darphane) dır-dir her biri için DB'nin p noktası yapmak p. ulaşılabilirlik-mesafe = BELİRLENMEDİ her biri için DB'nin işlenmemiş noktası p yapmak N = getNeighbors (p, eps) işlenmiş çıktı olarak p'yi sıralı listeye işaretleyin Eğer çekirdek-mesafe (p, eps, Dkphane)! = BELİRLENMEDİ sonra Tohumlar = boş öncelik kuyruğu güncellemesi (N, p, Tohumlar, eps, MinPts) her biri için Tohumlarda sonraki q yapmak N '= getNeighbors (q, eps) sıralı listeye işlenmiş çıktı q olarak q işaretleyin Eğer çekirdek mesafesi (q, eps, Dkphane)! = BELİRLENMEDİ yapmak güncelleme (N ', q, Tohumlar, eps, Dphane)
Update () 'de, öncelik kuyruğu Tohumlar, - mahalle ve , sırasıyla:



işlevi güncelleme (N, p, Seeds, eps, MinPts) dır-dir coredist = çekirdek mesafesi (p, eps, MinPts) her biri için o N cinsinden Eğer o işlenmedi sonra new-reach-dist = max (coredist, dist (p, o)) Eğer o. ulaşılabilirlik-mesafe == BELİRLENMEDİ sonra // o Tohumlar'da değil o. ulaşılabilirlik-mesafe = yeni-erişim-uzak Tohumlar. insert (o, new-reach-dist) Başka // o Seeds'de iyileştirme olup olmadığını kontrol edin Eğer yeni erişim uzaklığısonra o.reachability-distance = new-reach-dist Seeds.move-up (o, new-reach-dist)
Dolayısıyla OPTICS, noktaları en küçük erişilebilirlik mesafeleriyle açıklanmış belirli bir sıralamada çıkarır (orijinal algoritmada, çekirdek mesafesi de dışa aktarılır, ancak daha fazla işlem için bu gerekli değildir).
Kümeleri çıkarmak
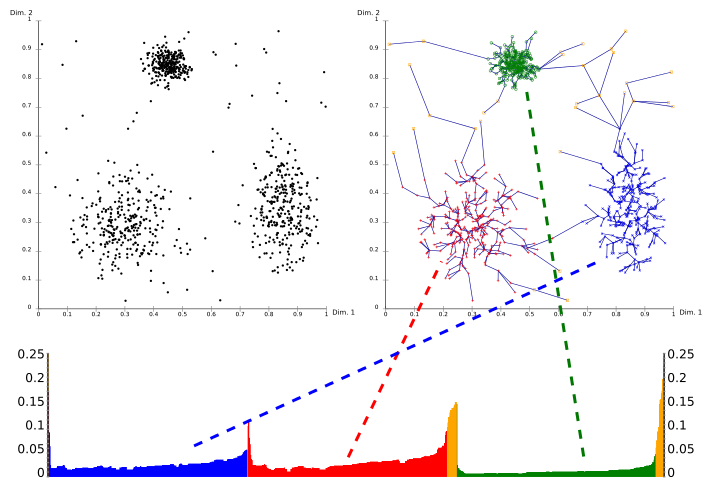
Bir ulaşılabilirlik arsa (özel bir tür dendrogram ), kümelerin hiyerarşik yapısı kolaylıkla elde edilebilir. X ekseninde OPTICS tarafından işlenen noktaların ve y ekseninde ulaşılabilirlik mesafesinin sıralandığı bir 2D çizimdir. Bir kümeye ait noktalar, en yakın komşularına düşük bir ulaşılabilirlik mesafesine sahip olduğundan, kümeler ulaşılabilirlik grafiğinde vadiler olarak görünür. Vadi ne kadar derinse, küme o kadar yoğun olur.
Yukarıdaki resim bu kavramı göstermektedir. Sol üst alanında, sentetik bir örnek veri seti gösterilmektedir. Sağ üst kısım, yayılan ağaç OPTICS tarafından üretilmiştir ve alt kısım OPTICS tarafından hesaplanan erişilebilirlik grafiğini gösterir. Bu grafikteki renkler etiketlerdir ve algoritma tarafından hesaplanmamıştır; ancak arsadaki vadilerin yukarıdaki veri setindeki kümelere nasıl karşılık geldiği gayet iyi görülmektedir. Bu görüntüdeki sarı noktalar gürültü olarak kabul edilir ve erişilebilirlik grafiklerinde herhangi bir vadi bulunmaz. Hiyerarşik bir sonuçta her yerde bulunan "tüm veriler" kümesi dışında genellikle kümelere atanmazlar.
Kümelerin bu grafikten çıkarılması, görsel incelemeden sonra x ekseninde bir aralık seçilerek, y ekseninde bir eşik seçilerek manuel olarak yapılabilir (sonuç daha sonra aynı şekilde bir DBSCAN kümeleme sonucuna benzerdir) ve minPts parametreleri; burada 0.1 değeri iyi sonuçlar verebilir) veya vadileri diklik, diz tespiti veya yerel maksimumlar ile tespit etmeye çalışan farklı algoritmalar tarafından yapılabilir. Bu şekilde elde edilen kümeler genellikle hiyerarşik ve tek bir DBSCAN çalıştırmasıyla elde edilemez.
Karmaşıklık
Sevmek DBSCAN OPTICS her noktayı bir kez işler ve bir - mahalle sorgusu bu işlem sırasında. Verilen bir uzamsal indeks mahalle sorgusu veren çalışma zamanı, genel çalışma zamanı elde edildi. Orijinal OPTICS makalesinin yazarları, DBSCAN ile karşılaştırıldığında 1,6 değerinde gerçek bir sabit yavaşlama faktörü bildirdiler. Değerinin Çok büyük bir değer bir komşu sorgunun maliyetini doğrusal karmaşıklığa yükseltebileceğinden, algoritmanın maliyetini büyük ölçüde etkileyebilir.


Özellikle seçme (veri kümesindeki maksimum mesafeden daha büyük) mümkündür, ancak ikinci dereceden karmaşıklığa yol açar, çünkü her komşu sorgu tüm veri kümesini döndürür. Uzamsal indeks bulunmadığında bile, bu, yığının yönetilmesinde ek bir maliyetle gelir. Bu nedenle, veri setine uygun şekilde seçilmelidir.

Uzantılar
OPTİKLER[4] bir aykırı değer tespiti OPTICS'e dayalı algoritma. Ana kullanım, farklı bir aykırı değer tespit yöntemi kullanmaya kıyasla düşük maliyetle mevcut bir OPTICS çalışmasından aykırı değerlerin çıkarılmasıdır. Daha iyi bilinen versiyon LOF aynı kavramlara dayanmaktadır.
DeLi-Clu,[5] Yoğunluk-Bağlantı-Kümeleme, tek bağlantılı kümeleme ve OPTİK, parametre ve OPTICS üzerinden performans iyileştirmeleri sunar.
Onun C'si[6] hiyerarşiktir alt uzay kümeleme OPTICS'e dayalı (eksen-paralel) yöntem.
HiCO[7] hiyerarşiktir korelasyon kümeleme OPTICS'e dayalı algoritma.
Tabak[8] daha karmaşık hiyerarşileri bulabilen HiSC'ye göre bir gelişmedir.
FOPTİKLER[9] rastgele projeksiyonlar kullanan daha hızlı bir uygulamadır.
HDBSCAN *[10] Kümelerden sınır noktaları hariç tutularak DBSCAN'ın iyileştirilmesine dayanır ve böylece Hartigan'ın yoğunluk seviyelerinin temel tanımını daha katı bir şekilde izler.[11]
Kullanılabilirlik
OPTICS, OPTICS-OF, DeLi-Clu, HiSC, HiCO ve DiSH'nin Java uygulamaları, ELKI veri madenciliği çerçevesi (birkaç mesafe işlevi için indeks hızlandırma ve ξ çıkarma yöntemi kullanılarak otomatik küme çıkarma ile). Diğer Java uygulamaları şunları içerir: Weka uzantısı (ξ küme çıkarma desteği yoktur).
R "dbscan" paketi OPTICS'in bir C ++ uygulamasını içerir (hem geleneksel dbscan benzeri hem de ξ küme çıkarma ile) k-d ağacı yalnızca Öklid mesafesi için dizin ivmesi için.
OPTICS'in Python uygulamaları şurada mevcuttur: PyClustering kütüphane ve içinde scikit-öğrenmek. HDBSCAN *, hdbscan kütüphane.
Referanslar
- ^ Kriegel, Hans-Peter; Kröger, Peer; Sander, Jörg; Zimek, Arthur (Mayıs 2011). "Yoğunluğa dayalı kümeleme". Wiley Disiplinlerarası İncelemeler: Veri Madenciliği ve Bilgi Keşfi. 1 (3): 231–240. doi:10.1002 / widm.30.
- ^ Mihael Ankerst; Markus M. Breunig; Hans-Peter Kriegel; Jörg Sander (1999). OPTICS: Kümeleme Yapısını Belirlemek İçin Noktaları Sıralama. ACM SIGMOD Uluslararası Veri Yönetimi Konferansı. ACM Basın. sayfa 49–60. CiteSeerX 10.1.1.129.6542.
- ^ Martin Ester; Hans-Peter Kriegel; Jörg Sander; Xiaowei Xu (1996). Evangelos Simoudis; Jiawei Han; Usama M. Fayyad (editörler). Gürültülü büyük uzamsal veritabanlarında kümeleri keşfetmek için yoğunluğa dayalı bir algoritma. İkinci Uluslararası Bilgi Keşfi ve Veri Madenciliği Konferansı Bildirileri (KDD-96). AAAI Basın. s. 226–231. CiteSeerX 10.1.1.71.1980. ISBN 1-57735-004-9.
- ^ Markus M. Breunig; Hans-Peter Kriegel; Raymond T. Ng; Jörg Sander (1999). "OPTICS-OF: Yerel Aykırı Değerleri Belirleme". Veri Madenciliği ve Bilgi Keşfi İlkeleri. Bilgisayar Bilimlerinde Ders Notları. 1704. Springer-Verlag. s. 262–270. doi:10.1007 / b72280. ISBN 978-3-540-66490-1.
- ^ Achtert, E .; Böhm, C .; Kröger, P. (2006). DeLi-Clu: En Yakın Çift Sıralamasına Göre Hiyerarşik Kümelemenin Sağlamlığını, Tamlığını, Kullanılabilirliğini ve Verimliliğini Artırma. LNCS: Bilgi Keşfi ve Veri Madenciliğinde Gelişmeler. Bilgisayar Bilimlerinde Ders Notları. 3918. s. 119–128. doi:10.1007/11731139_16. ISBN 978-3-540-33206-0.
- ^ Achtert, E .; Böhm, C .; Kriegel, H. P.; Kröger, P .; Müller-Gorman, I .; Zimek, A. (2006). Altuzay Kümelerinin Hiyerarşilerini Bulma. LNCS: Veritabanlarında Bilgi Keşfi: PKDD 2006. Bilgisayar Bilimlerinde Ders Notları. 4213. sayfa 446–453. CiteSeerX 10.1.1.705.2956. doi:10.1007/11871637_42. ISBN 978-3-540-45374-1.
- ^ Achtert, E .; Böhm, C .; Kröger, P .; Zimek, A. (2006). Korelasyon Kümelerinin Madencilik Hiyerarşileri. Proc. 18. Uluslararası Bilimsel ve İstatistiksel Veritabanı Yönetimi Konferansı (SSDBM). s. 119–128. CiteSeerX 10.1.1.707.7872. doi:10.1109 / SSDBM.2006.35. ISBN 978-0-7695-2590-7.
- ^ Achtert, E .; Böhm, C .; Kriegel, H. P.; Kröger, P .; Müller-Gorman, I .; Zimek, A. (2007). Alt Uzay Küme Hiyerarşilerinin Algılanması ve Görselleştirilmesi. LNCS: Veritabanlarındaki Gelişmeler: Kavramlar, Sistemler ve Uygulamalar. Bilgisayar Bilimlerinde Ders Notları. 4443. s. 152–163. CiteSeerX 10.1.1.70.7843. doi:10.1007/978-3-540-71703-4_15. ISBN 978-3-540-71702-7.
- ^ Schneider, Johannes; Vlachos, Michail (2013). "Rastgele projeksiyonlar yoluyla hızlı parametresiz yoğunluk tabanlı kümeleme". 22. ACM Uluslararası Bilgi ve Bilgi Yönetimi Konferansı (CIKM).
- ^ Campello, Ricardo J. G. B .; Moulavi, Davoud; Zimek, Arthur; Sander, Jörg (22 Temmuz 2015). "Veri Kümeleme, Görselleştirme ve Aykırı Değer Tespiti için Hiyerarşik Yoğunluk Tahminleri". Verilerden Bilgi Keşfi Üzerine ACM İşlemleri. 10 (1): 1–51. doi:10.1145/2733381.
- ^ J.A. Hartigan (1975). Kümeleme algoritmaları. John Wiley & Sons.